你用过的每一个 issue 追踪器都遵循同样的模式。有一个云服务。它有一个 Web UI。有人构建了一个与云 API 通信的 CLI。CLI 是二等公民:更慢、功能更少、总是落后一个 API 版本。
现在把这个架构翻转过来。从 CLI 开始。让它写入本地数据库。让数据库支持版本控制,拥有与你在源代码上使用的相同的分支和合并语义。然后在上面放一个原生桌面应用,直接读取相同的数据库文件,中间没有 API 层。
这就是 beads 和 Beadbox 做的事。而这种架构存在的原因是 AI agent。
问题:agent 不会点击按钮
如果你在协调一支 AI agent 团队(代码生成器、审查器、测试器、部署器),你需要它们创建 issue、更新状态、读取工作队列。它们无法认证到 Jira。它们无法操作 Linear 的 UI。它们需要一个写入本地数据库的 CLI,要快速,零网络依赖。
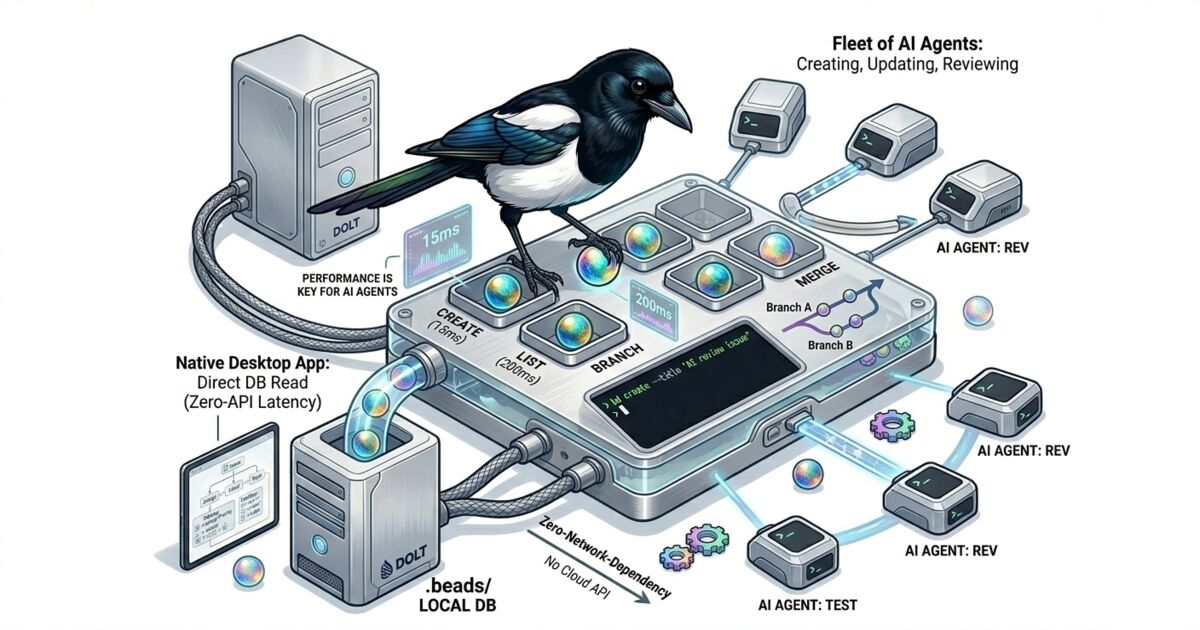
beads 就是这样的 CLI。它是一个开源的、Git 原生的 issue 追踪器,专为这种工作流设计。bd 命令创建、更新、列出和关闭 issue。每次写入都落在你仓库 .beads/ 目录中的本地 Dolt 数据库里。
数字很重要。bd create 大约需要 15ms。bd list 在 10,000 个 issue 上大约 200ms 返回。这些基准来自 beads 测试套件。当 agent 在紧密循环中处理工作项时,每次操作的毫秒数决定了你的 issue 追踪器是跟得上还是成为瓶颈。
为什么选 Dolt,而不是 SQLite?
Dolt 是一个实现了 Git 语义的 SQL 数据库。每次写入都是一次 commit。你可以用 dolt diff 查看两个时间点之间的变更。你可以用 dolt log 查看完整的审计历史。你可以用 dolt branch 和 dolt merge,使用你在代码上已经习惯的心智模型。
对于 issue 追踪,这意味着你的项目历史有两条平行的审计轨迹:git log 用于代码变更,dolt log 用于 issue 变更。你可以回答这样的问题:"当我们打 v2.1.0 标签时,issue 数据库是什么样的?"只需在 Dolt 历史中检出那个点。你可以为 issue 数据库创建分支来试验重新组织,然后合并回去或直接丢弃。
beads 在 v0.9.0 中移除了 SQLite 支持,全面转向 Dolt。版本控制语义不是锦上添花;它们是基础。当二十个 agent 写入同一个 issue 数据库时,你需要能够对这些数据进行 diff、分支和合并,具有与你对源代码控制相同的信心。
可选的协作通过 DoltHub 实现。将你的 issue 数据库推送到远程,从队友那里拉取变更。与 Git 相同的推/拉工作流,应用于结构化数据。
可视化层:Beadbox
Agent 在 CLI 上如鱼得水。人类则不然,至少在需要全局视角时不行。依赖图、epic 进度树、阻塞 issue 链:这些是空间问题,终端无法很好地渲染。
Beadbox 是一个基于 Tauri(不是 Electron)构建的原生桌面应用,读取 CLI 写入的同一个 .beads/ 目录。没有导入步骤、没有同步过程、没有 API 层。GUI 通过 fs.watch() 监听文件系统,检测 Dolt 数据库变更,并通过本地 WebSocket 广播更新。当 agent 运行 bd update BEAD-42 --status in_progress 时,状态标记在 Beadbox 中毫秒级变更。
以下是实际工作流的样子:
# 一个 agent 创建 issue
bd create --title "Migrate auth to OIDC" --type task --priority 1
# 另一个 agent 认领
bd update BEAD-42 --claim --actor agent-3
# 人类打开 Beadbox 看到完整的面板:
# 依赖图、epic 树、按状态/优先级/负责人过滤
# 不需要命令。看就行了。
# agent 完成工作并标记等待审查
bd update BEAD-42 --status ready_for_qa
# Beadbox 实时更新。QA agent 接手。
Agent 通过 CLI 写入。人类通过 GUI 阅读。两者操作同一个本地 Dolt 数据库。不需要调和、不会有过期缓存、不需要"让我刷新一下"。
Beadbox 支持 macOS、Linux 和 Windows。支持多工作区,可以在项目间切换而无需重启。
"本地优先"到底意味着什么
这个术语被过度使用了。以下是它对 beads 和 Beadbox 的具体含义:
不需要账号。 你不需要注册任何东西。安装 CLI,安装应用,指向一个目录。搞定。
不依赖云。 一切都运行在你的文件系统上。你的数据永远不会离开你的机器,除非你明确执行 dolt push 到远程。断网了?什么也不变。你继续工作。
不需要服务器。 没有需要管理的守护程序,没有需要运行的 Docker 容器。Dolt 数据库就是一个文件目录。CLI 读写这些文件。Beadbox 监听这些文件。
可选的协作。 当你确实想要共享时,推送到 DoltHub。你的队友拉取。issue 数据上的合并冲突与代码上的解决方式相同。但这是选择性加入的,不是必需的。
与其他方案对比。Jira 需要服务器(或 Atlassian Cloud)。Linear 需要账号和网络连接。GitHub Issues 需要一个在 GitHub 服务器上的仓库。即使是自托管选项如 Gitea 也需要运行一个 web 服务。
beads 需要一个目录。Beadbox 需要同一个目录加一次双击。
这是为谁准备的
如果你运行需要通过共享工作队列协调的 AI agent,并且希望人类能够可视化地监控和引导这些工作,这个技术栈就是为你的工作流而生的。
如果你独立管理项目,想要版本控制的 issue 追踪,存在代码旁边,不需要云账号,这个技术栈同样适用。
如果你需要 Jira 的企业级权限模型或 Linear 的分布式团队实时协作编辑,这不是合适的工具。beads 在设计上就是本地优先的。这是一种取舍,不是疏忽。
开始使用
从 github.com/steveyegge/beads 安装 beads CLI,然后安装 Beadbox:
brew tap beadbox/cask && brew install --cask beadbox
在任何项目中初始化 beads 数据库:
cd your-project
bd init
打开 Beadbox,指向该目录,你就在看你的 issue 面板了。不需要注册。不需要配置向导。不需要"连接你的 GitHub 账号"的弹窗。
Beadbox 在 beta 期间免费。