Claude Code에서 신뢰할 수 있는 출력을 얻는 개발자와 에이전트가 방금 만든 것을 되돌리는 데 하루의 절반을 보내는 개발자 사이에 점점 벌어지는 격차가 있다. 그 차이는 재능, 경험, 또는 비밀 프롬프트 엔지니어링 트릭이 아니다. 방법론의 문제다. AI 에이전트로 프로덕션 소프트웨어를 출시하는 개발자들은 그것을 뭐라고 부르든 하나의 패턴에 수렴했다: 에이전트가 코드를 쓰기 시작하기 전에 원하는 것을 정의하라.
이 글은 그 패턴에 이름을 붙인다. Spec-first 개발은 AI 지원 소프트웨어 엔지니어링을 위한 방법론이다. 모호한 "모범 사례"가 아니다. 정의된 단계, 명확한 체크포인트, 매 단계마다 구체적인 산출물이 있는 구조화되고 반복 가능한 생명주기다. Claude Code의 출력을 릴리스 일정에 걸 수 있을 만큼 예측 가능하게 만드는 방법을 찾고 있었다면, 이것이 그 프레임워크다.
Vibe Coding의 한계
"Vibe coding"은 2025년 초에 어휘에 들어왔다. 제안: 자연어로 원하는 것을 설명하고, AI가 쓰게 하고, 괜찮아 보일 때까지 반복한다. 프로토타입, 주말 프로젝트, 일회성 스크립트에는 vibe coding이 작동한다. 빠르게 기능하는 것을 얻고, 나중에 고장나도 위험은 낮다.
프로덕션 소프트웨어는 다른 제약 아래서 작동한다. 코드는 기존 코드베이스에 통합되어야 하고, 특정 요구사항을 충족해야 하며, 유지보수할 다른 사람들과의 접촉을 견뎌야 한다. Vibe coding이 이러한 제약을 만나면, 실패 모드는 예측 가능하다.
첫 번째 실패는 드리프트다. 기능을 대충 설명하고, 에이전트가 자신의 해석을 구현하고, 조정하면, 에이전트가 조정된 해석을 재구현한다. 세 번의 반복 후, 각 반복이 목표를 이동시켰기 때문에 원래 요구사항 중 하나도 충족하지 않는 작동하는 코드가 있다. 에이전트가 당신이 원한다고 생각하는 것에 수렴하고 있지, 실제로 필요한 것에가 아니다.
두 번째 실패는 보이지 않는 결정이다. 설명의 모든 공백은 에이전트가 조용히 내리는 결정이다. 데이터베이스 스키마, 에러 처리 전략, API 형태, 유효성 검사 규칙, 라이브러리 선택. 코드 리뷰 중에, 또는 더 나쁜 경우 프로덕션에서 이러한 결정을 발견한다. 에이전트가 나쁜 결정을 내린 것이 아니다. 지시받지 않은 결정을 내렸고, 그것들이 구현에 구워지기 전에 잡을 메커니즘이 없었다.
세 번째 실패는 리뷰 마비다. 에이전트가 아키텍처, 데이터 모델, 에러 코드, 엣지 케이스 처리를 선택한 600줄 diff는 전통적 의미에서 리뷰할 수 없다. spec에 대해 코드를 리뷰하는 것이 아니다. 코드에서 spec을 역공학하고, 동의하는지 결정하고 있다. 이것은 spec을 작성하는 것보다 더 오래 걸린다.
Vibe coding이 한계에 도달하는 이유는 두 가지 별개의 활동을 혼동하기 때문이다: 무엇을 만들지 결정하는 것과 그것을 만드는 것. Spec-first 개발은 이를 분리한다.
방법론으로서의 Spec-First
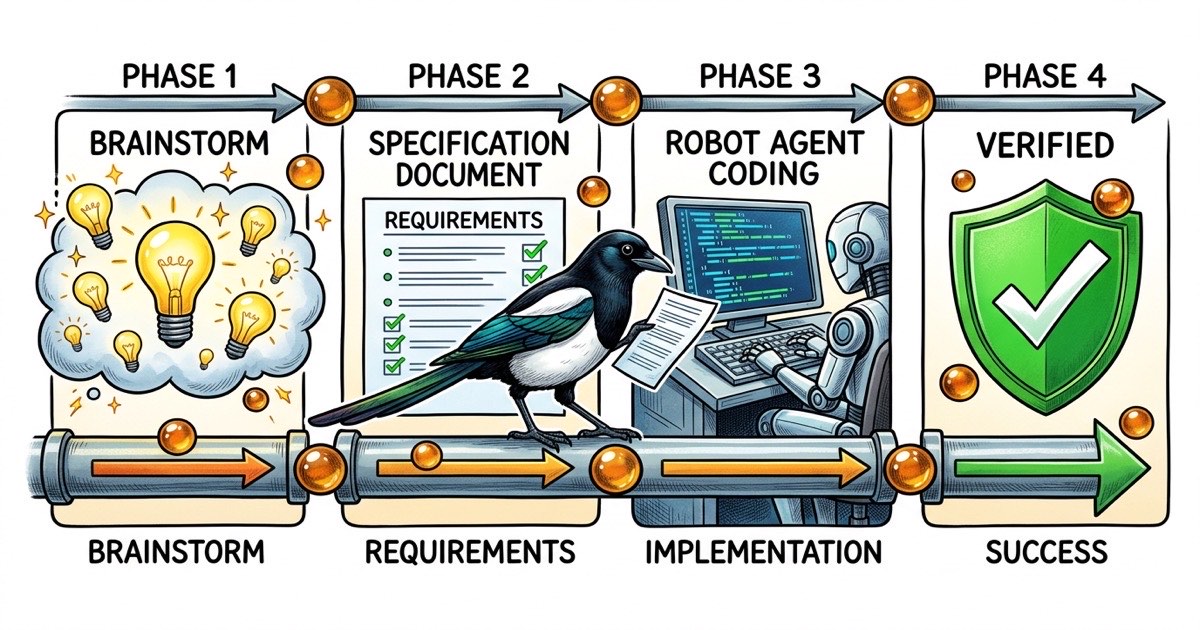
Spec-first 개발은 4단계 생명주기다. 각 단계는 구체적인 산출물을 생성한다. 각 전환에는 명확한 게이트 조건이 있다. 이 방법론은 모든 AI 코딩 에이전트와 작동하지만, 이 글의 예시는 커뮤니티가 가장 빠르게 반복하고 있는 Claude Code를 사용한다.
1단계: 브레인스토밍
당신과 에이전트(또는 당신만)가 문제 공간을 탐색한다. 제약은 무엇인가? 어떤 접근법이 존재하는가? 트레이드오프는 무엇인가? 이것은 대화식이다. 아무것에도 커밋하지 않는다. 영역을 매핑하고 있다.
게이트 조건: 선호하는 접근법이 있고 왜 대안이 아닌 이 접근법인지 설명할 수 있다.
Claude Code와의 브레인스토밍은 에이전트가 패턴과 라이브러리에 대한 폭넓은 지식을 가지고 있어 가치가 있다. 실수는 브레인스토밍에서 바로 코드로 뛰어가는 것이다. 브레인스토밍은 옵션을 표면화한다. 그 사이에서 선택하지 않는다. 그것은 당신이 한다.
2단계: Spec
결정을 적는다. 이것은 에이전트가 구현할 계약이다. spec은 유저 스토리가 아니고, Jira 티켓이 아니고, 산문 단락이 아니다. 다음을 포함하는 구조화된 문서다:
- 문제 진술: 무엇이 깨졌거나 빠졌는지, 구체적인 용어로
- 제안된 접근법: 브레인스토밍 단계에서 선택된 해결책
- 영향받는 파일: 에이전트가 어떤 파일을 건드려야 하는지(그리고 암묵적으로, 어떤 것을 건드리면 안 되는지)
- 수락 기준: "완료"를 정의하는 테스트 가능한 조건
- 범위 밖: 에이전트가 명시적으로 피해야 할 것
수락 기준이 가장 중요한 요소다. 각각은 관찰 가능한 결과를 가진 구체적인 액션이어야 한다. "인증이 작동해야 한다"는 기준이 아니다. "유효한 자격 증명을 제출하면 세션 토큰과 함께 200을 반환하고, 유효하지 않은 자격 증명을 제출하면 토큰 없이 401을 반환한다"가 기준이다.
범위 밖 섹션은 gold-plating을 방지한다. 이것 없이는, 에이전트가 인접한 코드를 "개선"하거나, 지저분해 보이는 파일을 리팩토링하거나, 관련되어 보이는 기능을 추가할 것이다. 에이전트가 요청되지 않은 작업에 쓰는 매 분은 당신이 요청되지 않은 작업을 리뷰하는 데 쓰는 매 분이다.
게이트 조건: 브레인스토밍에 없었던 사람이 이 spec을 읽고 올바른 것을 만들 수 있다.
3단계: 구현
에이전트가 spec에 대해 실행한다. 대화에 대해서가 아니다. 논의한 기억에 대해서가 아니다. 테스트 가능한 기준이 있는 구체적인 문서에 대해서다.
코드를 쓰기 전에, 에이전트는 계획을 생성한다: 할 예정인 변경 사항의 번호 목록, 어떤 파일을 수정할지, 결과를 어떻게 검증할지. 이 계획은 2분 체크포인트다. 읽고, 의도와 일치하는지 확인하고, 구현에 승인을 준다. 또는 오해를 잡고 수정한다. 어느 쪽이든, 20분이 아닌 2분을 투자했다.
Plan-before-code 패턴은 관료주의가 아니다. 전체 워크플로우에서 가장 레버리지가 높은 단일 개입이다. 대부분의 구현 실수는 코딩 에러가 아니다. 이해 에러다: 에이전트가 spec을 오해했다. 계획에서 이해 에러를 잡는 비용은 2분이다. 400줄 diff에서 잡는 비용은 20분이다. 프로덕션에서 잡는 비용은 하루다.
게이트 조건: 에이전트가 무엇이 만들어졌고 어떻게 검증되었는지에 대한 구체적인 주장이 담긴 완료 보고서를 게시했다.
4단계: 검증
당신 또는 QA 프로세스가 spec에 대해 구현을 확인한다. "괜찮아 보이는가?"가 아니라 "각 수락 기준을 충족하는가?"
검증은 기계적이다. spec에서 각 기준을 가져와, 테스트를 실행하고(명령 실행, 브라우저 열기, 이벤트 트리거), 결과를 기록한다: 통과 또는 실패. 실패한 기준은 3단계로 돌아간다. 검증은 구현과 함께 문서화되어 6개월 후 태스크를 읽는 누구나 정확히 무엇이 테스트되었는지 볼 수 있다.
게이트 조건: 모든 수락 기준에 기록된 통과/실패 결과가 있다.
이것이 완전한 생명주기다. 4단계, 4개의 산출물(접근법 근거, spec, 구현 계획, 검증 기록), 4개의 게이트 조건. 단계는 순차적이지만 가볍다. 중간 규모 기능의 경우, 1단계와 2단계는 15-20분이 걸린다. 3단계는 구현에 걸리는 시간만큼. 4단계는 5-10분.
왜 에이전트에서는 사람보다 더 중요한가
spec을 쓰는 모든 논거는 AI 이전부터 있었다. "코드 전에 요구사항을 써라"는 우리 대부분이 태어나기 전부터 있던 조언이다. 그렇다면 왜 이것을 AI 지원 개발에 특화된 것으로 프레이밍하는가?
에이전트가 비용 함수를 바꾸기 때문이다.
모호한 요구사항을 받은 인간 개발자는 멈추고 질문한다. "비밀번호 인증이야 SSO야?" "모바일에서 동작해야 해?" "토큰이 만료되면 어떻게 돼?" 각 질문은 구현을 올바른 목표로 밀어주는 미니 체크포인트다. 인간 개발자에게 모호한 spec의 비용은 몇 개의 Slack 스레드와 어쩌면 오후의 재작업이다.
모호한 요구사항을 받은 에이전트는 멈추지 않는다. 모든 모호한 결정을 조용히 내리고, 접근법에 커밋하고, 완성된 구현을 제시한다. 에이전트에게 모호한 spec의 비용은 완전히 틀릴 수 있는 완성된 구현, 그것이 틀렸다는 것을 발견하는 시간, 다시 하는 시간이다.
비대칭은 뚜렷하다. 에이전트는 인간 개발자보다 실행은 빠르고 판단은 나쁘다. spec의 모든 모호함은 판단 호출이고, 에이전트가 안내 없이 내리는 모든 판단은 결과가 의도와 일치하는지에 대한 동전 던지기다. Spec은 동전 던지기를 제거한다.
두 번째, 더 미묘한 이유가 있다. 에이전트는 반박하지 않는다. 나쁜 spec을 받은 시니어 엔지니어는 "X 때문에 이것은 말이 안 돼"라고 말할 것이다. 에이전트는 나쁜 spec을 충실히 구현하고 충실히 잘못된 출력을 생성한다. Spec-first 개발은 질문 없이 실행할 엔티티에 넘기기 전에 자신의 사고를 검증하도록 강제한다. Spec은 에이전트만을 위한 것이 아니다. 당신을 위한 것이다.
Plan-before-code 체크포인트
이 글에서 하나의 실천만 가져가고 나머지를 무시한다면, 이것을 가져가라.
에이전트가 코드를 쓰기 전에, 구현 계획 게시를 요구하라. 코드가 아니다. diff가 아니다. 무엇을 할 것인지의 구조화된 개요다.
계획은 이렇게 생겼다: 실행 순서의 번호 단계, 수정할 파일, 각 파일의 로직 변경, 검증 접근법. 에이전트는 이것을 약 30초 만에 생성한다. 당신은 약 2분에 읽는다. 그 2분 안에 다음을 잡을 수 있다:
- 범위 위반: 에이전트가 spec에 나열되지 않은 파일 수정을 계획한다
- 아키텍처 불일치: 에이전트가 기존 패턴과 충돌하는 접근법을 선택했다
- 누락된 단계: 계획이 수락 기준을 다루지 않는다
- 오버엔지니어링: 에이전트가 정당화되지 않는 추상화 구축을 계획한다
2분 계획 리뷰는 이러한 문제가 이미 만들어진 후 발견하는 20분 diff 리뷰를 대체한다. 소프트웨어 엔지니어링에서 가장 저렴한 품질 게이트다.
Plan-before-code 패턴의 상세 워크스루를 Claude Code를 활용한 Spec 주도 개발에 썼다. spec 템플릿과 완료 보고서 형식을 포함한다. 이 글은 패턴이 왜 작동하는지에 초점을 맞추고, 그 글은 어떻게 구현하는지에 초점을 맞춘다.
일급 단계로서의 검증
대부분의 개발자 워크플로우에서 가장 투자가 적은 단계는 검증이다. 에이전트가 "완료"라고 말한다. 개발자가 diff를 흘깃 본다. 머지가 일어난다. 사용자가 수락 기준의 엣지 케이스 3번에 부딪힌 2일 후 버그가 나타난다.
Spec-first 개발은 검증을 자체 산출물을 가진 공식 단계로 취급한다. 완료 보고서는 각 수락 기준을 구체적인 확인에 매핑한다:
- 기준: "워크스페이스 전환 시 저장된 필터 상태가 복원된다."
- 확인: 앱을 열고, 워크스페이스 A에서 필터를 설정하고, 워크스페이스 B로 전환하고, 워크스페이스 A로 돌아와서, 필터가 복원되었는지 관찰한다.
- 결과: 통과.
이것은 오버헤드가 아니다. 구현이 실제로 spec을 충족하는지 결정하는 단계다. 이것 없이는, spec은 위시리스트이고 수락 기준은 희망 사항이다.
검증 기록은 하류 문제도 해결한다: 코드 리뷰. 리뷰어가 풀 리퀘스트를 열 때, spec을 읽고, 검증 기록을 읽고, 완전한 컨텍스트로 diff를 리뷰한다. 리뷰어가 조사를 수행하는 것이 아니라 검증된 주장을 확인하고 있기 때문에 리뷰 시간이 줄어든다.
여러 에이전트를 병렬로 실행하고, 각각 다른 spec을 구현할 때, 검증 규율은 통제된 파이프라인과 "아마 작동할" 코드 더미의 차이다. 각 spec에는 기준이 있다. 각 구현에는 완료 보고서가 있다. 각 완료 보고서는 기준을 확인에 매핑한다. 기록된 검증 없이는 아무것도 출시되지 않는다.
이의와 솔직한 트레이드오프
Spec-first 개발은 무료가 아니다. 이의는 현실적이며 정면으로 다룰 가치가 있다.
"spec을 쓰면 느려진다." 단독으로는, 그렇다. 기능의 spec을 쓰는 데 15-20분이 걸린다. 하지만 구현과 리뷰 단계에서 그 시간(그리고 더)을 회수한다. 명확한 spec을 가진 에이전트는 모호한 프롬프트의 에이전트보다 더 자주 올바른 구현을 생산한다. 적은 반복, 적은 재작업, 짧은 리뷰. 실질적인 기능에 대한 순 효과는 더 느린 배달이 아니라 더 빠른 배달이다.
사소한 변경(변수 이름 변경, 오타 수정, 버전 범프)에는, spec은 불필요한 오버헤드다. Spec-first는 구현이 결정을 요구하는 작업을 위한 것이다. 변경이 기계적이고 모호하지 않으면, spec을 건너뛰어라.
"내 에이전트는 spec 없이도 충분히 좋다." 일부 태스크에는 아마 맞다. Claude Code는 간략한 설명에서 의도를 추론하는 능력이 뛰어나다. 문제는 에이전트가 모호한 지시에서 좋은 출력을 생산할 수 있는지가 아니다. 신뢰성 있게 그러는지다. 가끔의 재작업과 예측 불가능한 리뷰 시간에 편안하다면, vibe coding이 당신의 유스 케이스에 충분할 수 있다. Spec-first는 일관성과 예측 가능성이 중요할 때 효과를 발휘한다: 기능이 복잡할 때, 코드가 프로덕션에 갈 때, 다른 사람이 유지보수할 때.
"Spec이 낡는다." 타당한 우려다. 브레인스토밍 중에 쓴 spec은 현실과의 접촉을 견디지 못할 수 있다. 해결책은 spec을 건너뛰는 것이 아니다. 계획이 새로운 정보를 드러낼 때 spec을 업데이트하는 것이다. 에이전트의 계획이 spec의 접근법이 작동하지 않을 것을 보여주면, 진행하기 전에 spec을 수정하라. Spec은 구현 기간 동안 살아있는 문서다. 검증 후 역사적 기록이 된다.
"이건 그냥 워터폴이다." 아니다. 워터폴의 실패는 긴 피드백 주기의 큰 프로젝트를 위한 큰 spec이었다. Spec-first 개발은 태스크 레벨에서 작동한다: 기능이나 수정당 하나의 spec, 15-20분에 작성, 몇 시간에 구현, 같은 날 검증. 피드백 루프는 빠르다. Spec당 투자는 작다. Spec이 틀리면, 6개월 후가 아니라 계획 리뷰 중에 알게 된다.
Spec-First 생명주기를 위한 도구
이 방법론은 모든 태스크 시스템과 작동한다: GitHub Issues, Linear, Notion, 일반 텍스트 파일. 중요한 것은 spec, 계획, 구현 노트, 검증 결과가 모두 한 곳에, 하나의 태스크에 연결되어 있는 것이다.
이 워크플로우를 위해 설계된 시스템을 찾고 있다면, beads는 전체 생명주기를 보유하는 오픈소스, Git 네이티브 이슈 트래커다. 각 "bead"는 description(당신의 spec), 댓글 스레드(계획과 완료 보고서), 상태(open, in_progress, ready_for_qa, done), 의존성과 우선순위 같은 메타데이터를 갖는다. bd CLI는 터미널에서 작동하므로, 에이전트가 작업 환경을 떠나지 않고 spec을 읽고, 계획을 게시하고, 완료를 보고할 수 있다.
bd create --title "Persist filter state across workspaces" \
--description "## Problem ..." --type feature --priority p2
bd update bb-a1b2 --claim --actor eng1
bd comments add bb-a1b2 --author eng1 "PLAN: ..."
# After implementation:
bd comments add bb-a1b2 --author eng1 "DONE: ... Commit: a1b2c3d"
bd update bb-a1b2 --status ready_for_qa
전체 생명주기가 CLI에서 이루어진다. 6개월 후, bd show bb-a1b2는 무엇이 명세되고, 계획되고, 구축되고, 검증되었는지의 전체 이력을 반환한다.
하나의 에이전트를 이 생명주기로 실행할 때, CLI로 충분하다. 5개나 10개를 병렬로 실행하고, 각각 spec-implement-verify 파이프라인의 다른 단계에 있을 때, 파이프라인의 상태를 한눈에 봐야 한다. Beadbox는 어떤 spec이 열려 있는지, 어떤 계획이 리뷰를 기다리는지, 무엇이 진행 중인지, 무엇이 차단되었는지, 무엇이 검증 준비가 되었는지를 보여주는 실시간 대시보드다. 에이전트가 쓰는 같은 beads 데이터베이스를 모니터링하며, 상태가 변경되면 실시간으로 업데이트된다.
Spec-first 개발을 실천하는 데 Beadbox가 필요하지 않다. 방법론은 도구에 구애받지 않는다. 하지만 병렬 워크스트림이 파이프라인을 기억만으로는 추적할 수 없는 태스크 큐로 만들 때, 비주얼 레이어는 리뷰, 차단 해제, 출시 속도를 바꾼다.
더 넓은 변화
Spec-first 개발은 AI 코딩 에이전트가 나쁘다는 것에 대한 반응이 아니다. 안내 없이는 잘못된 것에 뛰어나다는 인식이다. 에이전트는 비범하게 유능한 실행자다. 올바른 구문을 쓰고, 패턴을 따르고, 보일러플레이트를 처리하고, 어떤 인간도 맞출 수 없는 볼륨을 생산한다. 부족한 것은 무엇을 구축할지에 대해 좋은 결정을 내릴 컨텍스트다. 그 컨텍스트는 당신에게서 오고, spec이 그 매개체다.
AI 지원 엔지니어링에서 번성할 개발자는 최고의 프롬프트를 쓰는 사람이 아니다. 최고의 spec을 쓰는 사람이다. 프롬프트는 일시적이다. Spec은 지속적이다. 프롬프트는 단일 상호작용에 최적화한다. Spec은 생명주기에 최적화한다: 브레인스토밍, 정의, 구현, 검증.
이것은 에이전트가 더 똑똑해질 때까지의 일시적 우회가 아니다. 모델이 개선되어도 근본적 비대칭은 남는다: 인간은 비즈니스가 무엇을 필요로 하는지 알고, 에이전트는 코드를 어떻게 쓰는지 안다. Spec은 둘을 연결한다. 더 나은 모델은 spec을 더 빠르게 실행하겠지만, spec 자체의 필요성은 사라지지 않는다. 스케일할수록 더 중요해진다. 더 많은 에이전트가 모호한 지시에 대해 실행하면 더 발산하는 출력을 생산하기 때문이다.
Claude Code 에이전트를 실행하고 결과가 일관되지 않거나, 리뷰에 너무 많은 시간이 걸리거나, 병렬 워크스트림 조정에 어려움을 겪고 있다면, 이것을 시도하라: 다음 기능 전에, 테스트 가능한 수락 기준이 있는 spec을 쓰는 데 15분을 투자하고, 에이전트에게 코딩 전 계획 게시를 요구하고, 출력을 기준별로 검증하라. 한 사이클이면 차이를 알 수 있다.
이런 워크플로우를 구축하고 있다면, Beadbox에 GitHub에서 스타를 주세요.