MCP 서버 하나로 시작했습니다. 파일 접근, Claude Code 에이전트가 프로젝트를 읽고 쓸 수 있도록. 합리적인 선택이었습니다.
그 다음 웹 검색을 추가했습니다. 그 다음 GitHub. 그 다음 데이터베이스 도구, 에이전트가 스키마를 직접 쿼리할 수 있도록. 그 다음 Slack, 에이전트가 요구사항 스레드를 확인해야 했으니까. 그 다음 내부 위키를 위한 문서 도구.
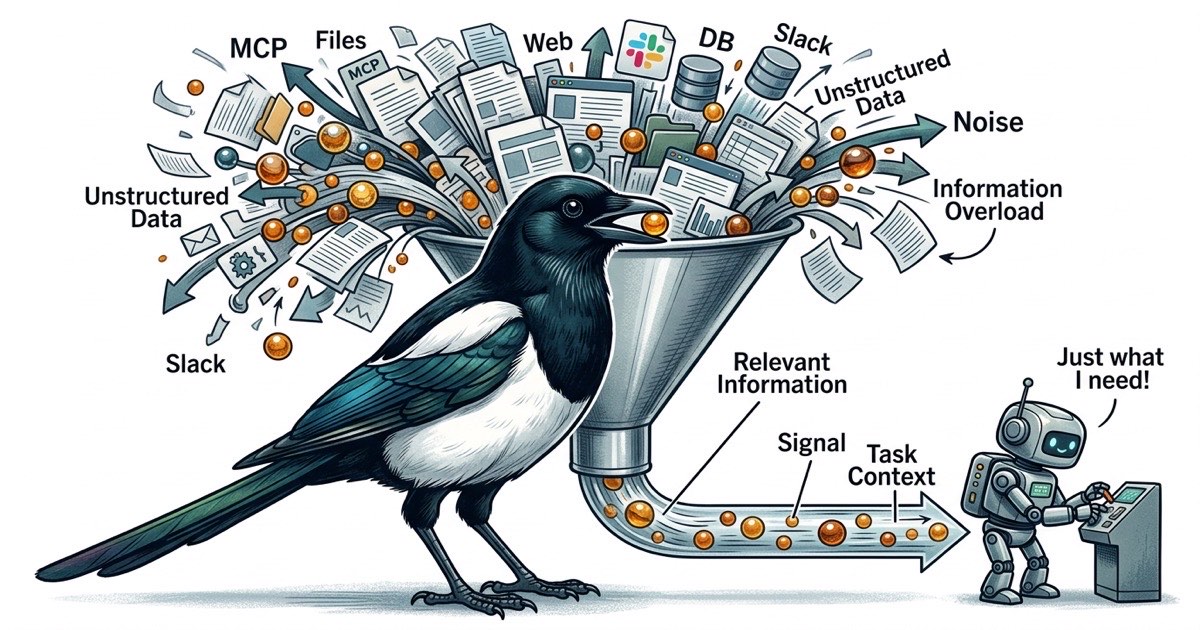
MCP 서버 6개. 각각이 에이전트 컨텍스트에 도구 스키마를 등록합니다. 각각이 에이전트가 할 수 있는 일의 표면적을 넓히고, 도구 설명에 더 많은 토큰이 소비되며, 에이전트가 본래 작업에서 벗어날 기회가 늘어납니다.
에이전트는 여전히 좋은 코드를 작성합니다. 하지만 더 느려졌고, 결과물의 예측 가능성이 떨어졌습니다. 착각이 아닙니다. 컨텍스트 윈도우가 병목이고, 그걸 배관으로 채우고 있는 겁니다.
누적 문제
MCP 서버는 강력합니다. Model Context Protocol은 Claude Code에 외부 시스템 접근을 제공하고, 각 통합은 실제로 문제를 해결합니다. 파일 접근으로 에이전트가 코드베이스를 읽을 수 있습니다. 웹 검색으로 문서를 찾을 수 있습니다. GitHub 통합으로 PR 상태를 확인할 수 있습니다.
문제는 에이전트의 모든 필요를 또 다른 MCP 추가로 해결하기 시작할 때 시작됩니다.
에이전트가 데이터베이스 스키마를 확인해야 한다? Postgres MCP 추가. 에이전트가 Confluence 페이지를 읽어야 한다? Confluence MCP 추가. 에이전트가 Slack 메시지를 보내야 한다? Slack MCP 추가. 각각은 개별적으로 정당합니다. 하지만 합쳐지면 결과물 품질이 떨어질 때까지 알아채기 어려운 문제를 만듭니다.
각 MCP 서버는 대화 컨텍스트에 도구를 등록합니다. 파일 접근 MCP는 5-10개의 도구를 등록할 수 있습니다. 데이터베이스 MCP는 또 몇 개를. GitHub MCP는 더. MCP 서버 6개를 갖고 있으면, 에이전트는 코드 한 줄을 읽기 전에 컨텍스트 윈도우에 수십 개의 도구 정의를 들고 있습니다.
이 도구 정의들은 공짜가 아닙니다. 토큰을 소비합니다. 더 중요한 건, 에이전트의 주의력을 놓고 경쟁한다는 것입니다. 에이전트가 40개의 도구를 사용할 수 있을 때, 모든 결정 지점이 분기 질문이 됩니다: 파일 도구를 쓸까, 검색 도구를 쓸까, 데이터베이스 도구를 쓸까, GitHub 도구를 쓸까? 에이전트는 문제를 해결하기 위해 정보를 사용하는 대신 정보를 얻는 방법을 결정하는 데 인지 예산을 씁니다.
컨텍스트는 유한하다. 주의력은 더 부족하다.
Claude Code의 컨텍스트 윈도우는 큽니다. 이것이 위험한 착각을 만듭니다: 결과 없이 계속 정보를 추가할 수 있다는 착각.
실제로는 컨텍스트 윈도우가 채워지기 훨씬 전에 에이전트 성능이 저하됩니다. 문제는 용량이 아닙니다. 신호 대 잡음비입니다. 200K 토큰 컨텍스트 윈도우를 가진 에이전트는, 관련 정보가 도구 스키마, API 응답, 관련 없는 파일 내용 사이에 흩어져 있는 150K 토큰보다, 집중된 관련 정보 50K 토큰으로 더 잘 수행합니다.
브라우저 탭이 너무 많을 때 사람들이 겪는 것과 같은 문제입니다. 정보는 기술적으로 이용 가능합니다. 찾는 데 필요 이상으로 오래 걸립니다. 관련 컨텍스트가 노이즈에 의해 작업 기억에서 밀려나서 이미 본 것을 다시 읽게 됩니다.
에이전트에서는 이것이 다음과 같이 나타납니다:
토끼굴. 에이전트에 데이터베이스 도구가 있으니 스키마를 쿼리합니다. 스키마가 흥미로우니 데이터를 쿼리합니다. 데이터에서 예상치 못한 것이 발견되니 더 조사합니다. 20분 후, 데이터베이스 내용에 대한 철저한 분석은 있지만 요청한 기능의 진행은 제로입니다.
도구 혼동. 많은 도구가 사용 가능하면 에이전트가 가끔 잘못된 것을 선택합니다. 로컬 파일에 이미 있는 문서를 웹 검색으로 찾습니다. 작업 설명에 답이 있는데 데이터베이스를 쿼리합니다. 잘못된 도구 선택 하나하나가 토큰을 낭비하고 노이즈를 만듭니다.
희석된 집중력. 에이전트의 "주의력"은 각 생성 내에서 유한한 자원입니다. 컨텍스트에 파일 접근, 웹 검색, 데이터베이스 쿼리, GitHub 작업, Slack 메시지, 위키 조회를 위한 도구 스키마가 포함되어 있으면, 에이전트는 실제 요청을 처리하기 전에 그 모든 것을 처리합니다. 작업이 도구와 인지적 우선순위를 놓고 경쟁합니다.
경계가 있는 컨텍스트: 도구 비대화의 대안
"내 에이전트가 정보 X가 필요하다"에 대한 반사적 대응은 에이전트에게 X를 가져오는 도구를 주는 것입니다. 하지만 다른 접근법이 있습니다: X를 작업에 넣는 것입니다.
이것이 경계가 있는 컨텍스트 패턴입니다. 에이전트에게 모든 것에 대한 접근을 주고 관련 있는 것을 찾기를 바라는 대신, 각 에이전트에게 작업을 완료하는 데 필요한 모든 것을 포함하는 작업을 줍니다. 에이전트가 컨텍스트를 찾는 게 아닙니다. 컨텍스트가 전달됩니다.
차이는 구조적입니다. MCP 비대화가 있는 경우 에이전트 워크플로우는:
- 작업 읽기
- 어떤 정보가 부족한지 파악
- 다양한 도구를 사용해 정보 수집
- 정보 종합
- 실제 작업 수행
경계가 있는 컨텍스트에서는:
- 작업 읽기 (필요한 모든 컨텍스트가 포함됨)
- 실제 작업 수행
첫 번째 워크플로우의 2-4단계는 단순한 오버헤드가 아닙니다. 일이 잘못되는 곳이 바로 거기입니다. 에이전트가 너무 많은 정보를 수집하거나, 잘못된 정보를 수집하거나, 흥미롭지만 관련 없는 데이터에 주의가 분산됩니다. 모든 도구 호출이 잠재적인 우회입니다.
경계가 있는 컨텍스트는 에이전트가 도구를 사용할 수 없다는 뜻이 아닙니다. 파일 접근은 코드 읽기와 쓰기에 여전히 필요합니다. 하지만 정보적 컨텍스트(무엇을 만들지, 왜, 어떤 파일, 수락 기준이 무엇인지)는 작업 안에 있어야지, 에이전트가 쿼리해야 하는 도구 안에 있으면 안 된다는 뜻입니다.
작업을 컨텍스트 컨테이너로 구조화하기
컨텍스트 컨테이너로 기능하는 작업은 일반적인 Jira 티켓이나 GitHub Issue와 다릅니다. 자체적으로 완결됩니다. 읽는 에이전트는 배경 정보를 위해 외부 시스템을 조회하지 않고도 작업을 시작하는 데 필요한 모든 것을 가져야 합니다.
실제로는 이렇게 보입니다:
Title: Add rate limiting to /api/search endpoint
Description:
The /api/search endpoint currently has no rate limiting.
Add a token bucket rate limiter at 100 requests/minute per IP.
Files to modify:
- server/middleware/rate-limit.ts (create new)
- server/routes/search.ts (apply middleware)
- server/config.ts (add RATE_LIMIT_RPM env var)
Acceptance criteria:
- Requests beyond 100/min from same IP return 429
- Rate limit resets after 60 seconds
- Config value overridable via environment variable
- Existing tests still pass
Context:
- We use Express middleware pattern (see server/middleware/auth.ts for example)
- The config module uses dotenv (see server/config.ts lines 1-15)
- No Redis available; use in-memory store. This is a single-instance app.
Dependencies: None. This can run independently.
작업에 무엇이 내장되어 있는지 주목하세요. 에이전트는 어떤 파일을 건드려야 하는지, 어떤 패턴을 따라야 하는지, 어떤 제약이 있는지(Redis 없음), "완료"가 정확히 어떻게 보이는지 알고 있습니다. 스키마를 확인하기 위한 데이터베이스 MCP가 필요 없습니다. 미들웨어 패턴을 찾기 위한 위키 도구가 필요 없습니다. 설정 접근법을 이해하기 위해 코드베이스를 검색할 필요가 없습니다. 모든 것이 작업에 있습니다.
이렇게 작업을 작성하려면 사전 노력이 더 필요합니다. 일반적인 티켓은 "검색 엔드포인트에 레이트 리미팅 추가"라고 말하고 나머지는 에이전트에게 맡길 수 있습니다. 하지만 그 파악 과정이 바로 MCP 비대화가 오는 곳입니다: 에이전트가 정보가 필요하니 도구를 주고, 도구가 컨텍스트를 먹습니다.