3つのことを同時に処理する必要があるfeatureがある。単一のClaude Codeセッション内でsubagentをspawnして並列作業させることもできる。あるいは、作業を3つの独立したタスクに分割し、それぞれを別のtmuxペインで動く別々のエージェントに渡し、互いを知らない状態で走らせることもできる。
どちらのアプローチも作業を並列化する。解決する問題が違う。間違った方を選ぶと、コーディネーションオーバーヘッドでコンテキストウィンドウを燃やすか、元のタスクより修正に時間がかかるmergeコンフリクトを生むことになる。
これは13体のClaude Codeエージェントを同じコードベースで走らせながら毎日使っている判断フレームワークだ。理論ではない。境界がどこにあるか分かるまで十分に間違えた結果だ。
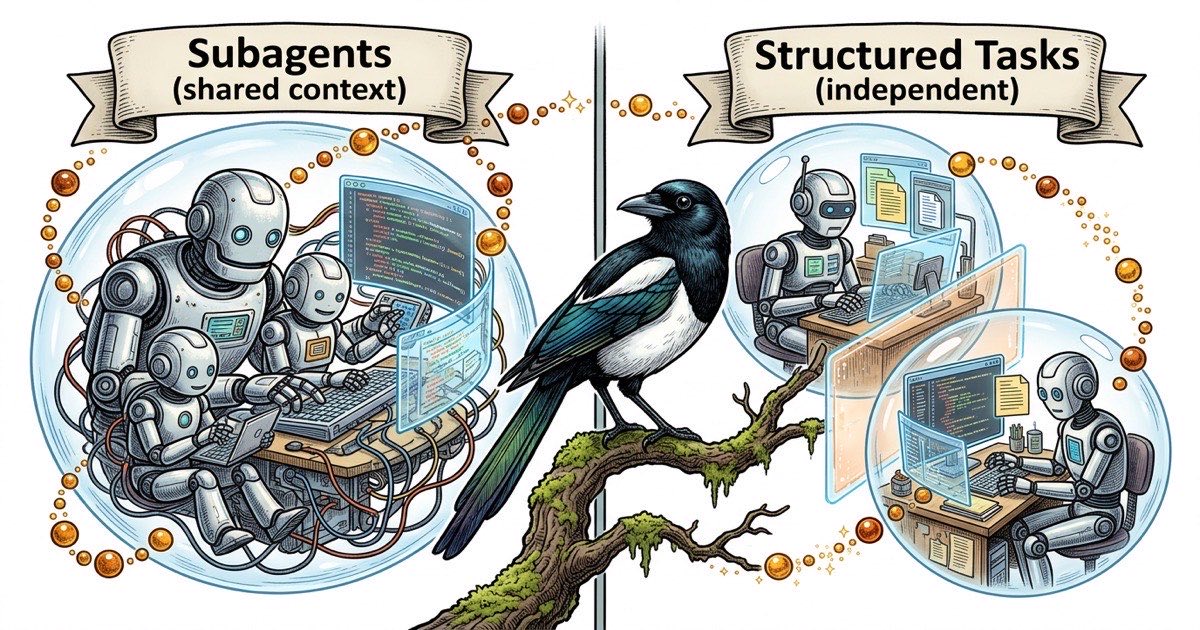
2種類の並列性
Claude Codeは作業を並行実行する2つの異なる方法をサポートしている。
Subagentは単一のClaude Codeセッション内でspawnされる子プロセスだ。親エージェントが複数のsubagentを起動し、それぞれが問題の一部に取り組み、結果を収集する。同じ作業ディレクトリと親のコンテキストを共有する。単一プロセス内のスレッドと考えればいい。
Parent agent
├── Subagent A: "Search lib/ for all usages of parseConfig"
├── Subagent B: "Search server/ for all usages of parseConfig"
└── Subagent C: "Search components/ for all usages of parseConfig"
別々のエージェントは独立したClaude Codeセッションで実行され、通常は別々のtmuxペインに配置される。それぞれが独自のコンテキストウィンドウ、独自のCLAUDE.mdアイデンティティファイル、独自のコードベースビューを持つ。メモリを共有しない。アーティファクトを通じてコミュニケーションする:タスクコメント、ステータス更新、コミット済みコード。共有状態のない別々のプロセスと考えればいい。
tmux pane 1: eng1 agent → "Build the REST endpoint"
tmux pane 2: eng2 agent → "Build the React component"
tmux pane 3: qa1 agent → "Write integration tests for both"
メンタルモデルが重要なのは、ユニット間の作業フローを決定するからだ。Subagentはデータを安価に親に返せる。別々のエージェントはファイルシステム、git、または外部タスクトラッカーを通じてデータを渡す。
Subagentが勝つとき
作業が状態を共有し、結果が収束する必要があるときにsubagentを使う。
並列リサーチ。 5つのディレクトリでパターンを検索し、3つのドキュメントファイルを読み、発見を1つの推奨にまとめる必要がある。Subagentはそれぞれ検索パスを担当し、結果を返し、親がシリアライゼーションオーバーヘッドなしで組み合わせられる。
同じデータに対する独立した変換。 モジュールをリファクタリングしていて、型定義、テスト、ドキュメントを1つの一貫した変更で更新する必要がある。各subagentが1ファイルを担当するが、親はcommit前に3つの結果すべてを見るため一貫性を保証できる。
高速な探索。 デバッグ中で、git log、テスト出力、ランタイム設定を同時に確認する必要がある。Subagentが3つすべてを並列に収集し、親が診断を合成する。
パターン:展開し、収集し、結合結果に基づいて行動する。 並列化の最後に親がすべてのoutputについてまとめて推論する必要があるなら、subagentが正しいツールだ。
Subagentが不得意なもの: ブランチあたり数分以上かかるもの、重複するパスのファイルを変更するもの、独立した検証が必要なもの。Subagentは作業ディレクトリを共有するため、2つのsubagentが同じファイルに書き込むと互いの作業を破壊する。そしてコンテキストを共有するため、長時間実行のsubagentは親の利用可能なウィンドウを食い潰す。
別々のエージェントが勝つとき
作業が独立して検証でき、意味を持つために共有コンテキストを必要としないときに別々のエージェントを使う。
同じfeatureの異なるコンポーネント。 「APIエンドポイントを構築する」と「それを呼び出すフロントエンドを構築する」はインテグレーションまで独立している。APIエンジニアはReactコンポーネントをコンテキストに必要としない。フロントエンドエンジニアはデータベーススキーマを必要としない。それぞれにスコープされたCLAUDE.mdを持つ専用エージェントを与えることで、コンテキストをクリーンに保ち、一方のエージェントの複雑さが他方の作業に漏れることを防ぐ。
異なるアクセプタンスクライテリア。 タスクAがエンドポイントが正しいJSON形式で200を返したとき完了、タスクBがコンポーネントが適切なエラー状態でデータをレンダリングしたとき完了なら、それらは別々の検証ターゲットだ。QAエージェントがそれぞれを独立に検証できる。Subagentは結合されたoutputを生成するため独立してQAできない。
コードベースの異なる部分に触れる作業。 ファイルオーナーシップはmergeコンフリクトを防ぐ最もシンプルな方法だ。エージェントAがserver/を所有し、エージェントBがcomponents/を所有する。どちらも相手のテリトリーに入らない。Subagentでこれを試みると、親がファイルロックを管理する必要があり、並列化の意味がなくなる。
異なる時間軸のタスク。 一方のタスクが10分、もう一方が2時間かかる。Subagentでは親が最も遅い子を待つ。別々のエージェントなら、短いタスクが完了し、検証され、shipされる間に長いタスクがまだ実行中だ。
パターン:発射し、忘れ、個別に検証する。 作業の各ピースが単独で成立し、単独でチェックできるなら、構造化タスクを持つ別々のエージェントの方がクリーンだ。
ハンドオフの問題
本当の判断ポイントはハンドオフに帰着する。
Subagentのハンドオフは安い。子が同じコンテキスト内で親にデータを返す。シリアライゼーションなし、ファイル書き込みなし、ステータス更新の待機なし。親が3つのsubagentを起動し、3つの結果が返り、親は必要なものをすべて持っている。
別々のエージェント間のハンドオフは高コストだが永続的だ。エージェントAが作業を完了し、コードをcommitし、タスクステータスを更新し、何をしたかコメントする。エージェントBがそのシグナルを拾い(コーディネーター経由またはタスクトラッカーのポーリングで)、依存作業を開始する。オーバーヘッドは現実的だ:タスクシステム、ステータスプロトコル、エージェントが他のエージェントの作業を発見する方法が必要だ。
経験則:並列ユニット間で2回以上のハンドオフが必要なら、subagentを使う。 単一のfan-out-and-gatherなら、subagentがシンプルだ。エージェントAのoutputがエージェントBのinputで、それがエージェントCのinputになるなら、別々のエージェントのコーディネーションコストは正当化される。各ハンドオフが検証済みのcommit済みアーティファクトを生成し、エージェントがクラッシュしたりコンテキスト制限に達しても失われないからだ。
具体的な例。次のことが必要だ:
- ユーザーデータを返すすべてのAPIエンドポイントを見つける
- それぞれにrate limitingを追加する
- 新しいrate limitのテストを書く
- APIドキュメントを更新する
ステップ1と2は密結合だ。検索結果(ステップ1)が直接変更(ステップ2)にフィードする。Subagentが検索を処理し、親が変更を適用する。これはsubagentパターンだ。
ステップ3と4は互いに独立だがステップ2に依存する。テストには実際のエンドポイントコードが必要だ。ドキュメントには最終的なAPI形式が必要だ。これらは別々のエージェント用の別々のタスクで、それぞれ独自のアクセプタンスクライテリアを持ち、それぞれ独立して検証可能だ。
Beadbox はこの問題を解決します。
エージェントフリート全体が今何をしているか、リアルタイムで把握できます。
ベータ期間中は無料でお試し →
構造化タスク分割の実践
答えが「別々のエージェント」のとき、featureを互いに干渉せずに並列実行できるタスクに分解する方法が必要だ。
分解プロセス:
1. 依存関係グラフを特定する。 何かを分割する前に、何が何に依存するかをマッピングする:
Feature: User profile page with activity feed
- API endpoint: GET /users/:id/profile (no deps)
- API endpoint: GET /users/:id/activity (no deps)
- React component: ProfileHeader (depends on profile API)
- React component: ActivityFeed (depends on activity API)
- Integration test: profile page end-to-end (depends on all above)
2つのAPIエンドポイントには依存関係がない。並列実行できる。2つのReactコンポーネントはそれぞれ1つのAPIに依存する。インテグレーションテストはすべてに依存する。
2. オーナーシップの境界を引く。 各タスクにファイルスコープを割り当てる。Profile APIエージェントはserver/routes/profile.tsとserver/services/profile.tsを所有する。Activity APIエージェントはserver/routes/activity.tsとserver/services/activity.tsを所有する。どちらも相手のファイルに触れない。共有ユーティリティの変更が必要な場合、一方のエージェントが変更を作成し、もう一方が待つ。
3. タスクごとのアクセプタンスクライテリアを定義する。 各タスクには他のタスクを見ずに検証できる明確な「完了」条件が必要だ。「Profile APIが正しい形式で200を返す」は検証可能だ。「プロフィールページが動く」は検証できない。インテグレーションに依存するからだ。
4. ハンドオフアーティファクトを指定する。 下流エージェントは上流エージェントから何を必要とするか?通常:既知のブランチ上のcommit済みコード、ステータス更新、インターフェースコントラクトを記述するコメント(API形式、コンポーネントprops、関数シグネチャ)。
この分解により、曖昧な「プロフィールページを作る」が明示的な依存関係と検証基準を持つ5つの個別タスクに変わる。各タスクは必要なコンテキストだけを持ち、それ以上は持たないエージェントに割り当てられる。
Beadsによる構造化分割
ここで本物のタスクシステムを持つことが重要になる。5つの並列タスクを付箋とターミナル出力で追跡することはできない。
beadsはローカルファーストのissueトラッカーで、この分解をネイティブにモデル化する。Epicがfeatureを表す。Childrenがサブタスクを表す。Dependenciesがprerequisiteが完了するまでエージェントが作業を開始するのを防ぐ。
実践での分割はこうなる:
# Create the epic
bd create --title "User profile page with activity feed" \
--type epic --priority p2
# Create subtasks as children
bd create --title "GET /users/:id/profile endpoint" \
--parent bb-epic1 --type task --priority p2
bd create --title "GET /users/:id/activity endpoint" \
--parent bb-epic1 --type task --priority p2
bd create --title "ProfileHeader React component" \
--parent bb-epic1 --type task --priority p2 \
--deps bb-profile-api
bd create --title "ActivityFeed React component" \
--parent bb-epic1 --type task --priority p2 \
--deps bb-activity-api
bd create --title "Profile page integration test" \
--parent bb-epic1 --type task --priority p2 \
--deps bb-profile-header,bb-activity-feed
構造が明示的になった。bd show bb-profile-headerを実行するエージェントは、profile APIタスクに依存していることを確認する。そのタスクがまだ完了していなければ、エージェントは開始しないと分かる。APIエージェントが完了してタスクを完了マークすると、フロントエンドエージェントの依存関係がクリアされる。
エージェントのワークフローは予測可能なループに従う:
# Agent claims the task
bd update bb-profile-api --claim --actor eng1
# Agent comments its plan before writing code
bd comments add bb-profile-api --author eng1 "PLAN:
1. Create route handler at server/routes/profile.ts
2. Add service layer at server/services/profile.ts
3. Return shape: { id, name, avatar, bio, joinedAt }
4. Test: curl localhost:3000/users/1/profile returns 200"
# Agent implements, tests, commits
# ...
# Agent marks done with verification steps
bd comments add bb-profile-api --author eng1 "DONE: Profile endpoint implemented.
Returns { id, name, avatar, bio, joinedAt }.
Verified: curl returns 200 with correct shape.
Commit: abc1234"
bd update bb-profile-api --status ready_for_qa
すべてのステップが記録される。QAエージェントはDONEコメントを読み、検証方法を正確に把握する。下流エージェントはPLANコメントを読み、コードが完成する前にAPIコントラクトを把握する。
これはプロセスのためのオーバーヘッドではない。5つの並列エージェントが5つの互換性のないコードを生産するのを防ぐ最小限の構造だ。
デフォルトの選択
数ヶ月間プロダクション作業で並列エージェントを運用した結果、従っている判断ツリーがこれだ:
Subagentから始めるとき:
- タスクがリサーチまたは探索(検索、読み取り、比較)
- 結果が単一のアクションに収束する必要がある
- 作業全体が1つのコンテキストウィンドウに収まる
- 各並列ユニットの独立した検証が不要
別々のタスクに切り替えるとき:
- 作業の異なる部分が異なるファイルに触れる
- 各ピースが独自のアクセプタンスクライテリアを持つ
- QAにピースを独立して検証してほしい
- 作業が十分に長く、一方が他方より数時間早く完了する可能性がある
- エージェントが異なるコンテキストを必要とする(フロントエンドエージェントにデータベース内部は不要)
複雑なfeatureのハイブリッドアプローチ:
リサーチと計画フェーズにsubagentを使い(展開し、情報を集め、プランを合成)、実装を独立したエージェント用の別々のタスクに分解する。Spec-driven developmentワークフローがここに自然にフィットする:subagentを持つ単一のエージェントがspecを書き、specがマルチエージェントフリート用のタスクに分解される。
分割の可視化
5つか10の構造化タスクに依存関係がある状態で、ターミナルで進捗を追跡するのは困難になる。bd listはフラットなリストを表示する。どのタスクがブロックされているか、どれが開始可能か、epicがどこまで進んでいるかは表示されない。
これがBeadboxが解決する問題だ。同じbeadsデータベースを読み、進捗インジケーター、依存関係、エージェント割り当てを持つepicツリーをレンダリングする。どのサブタスクが完了し、どれがprerequisiteでブロックされ、どれがエージェントにピックアップされる準備ができているかが見える。--depsで指定した依存関係グラフが並列作業のビジュアルマップになる。
エージェントがタスクを完了してステータスを更新すると、Beadboxがリアルタイムで変更を反映する。リフレッシュ不要、bd listの再実行不要。ツリーが更新され、プログレスバーが動き、ブロックされたタスクが依存関係の解決とともにアンブロックされる。
同じデータ。ただ見える。
このようなワークフローを構築しているなら、GitHubでBeadboxにスターを。
Like what you read?
Beadbox is a real-time dashboard for AI agent coordination. Free during the beta.