最初は1つのMCPサーバーから始めました。ファイルアクセス。Claude Codeエージェントがプロジェクトを読み書きできるようにするためです。妥当な判断でした。
次にウェブ検索を追加しました。次にGitHub。次にデータベースツール、エージェントがスキーマを直接クエリできるように。次にSlack、エージェントが要件のスレッドを確認する必要があったから。次に社内Wikiのためのドキュメントツール。
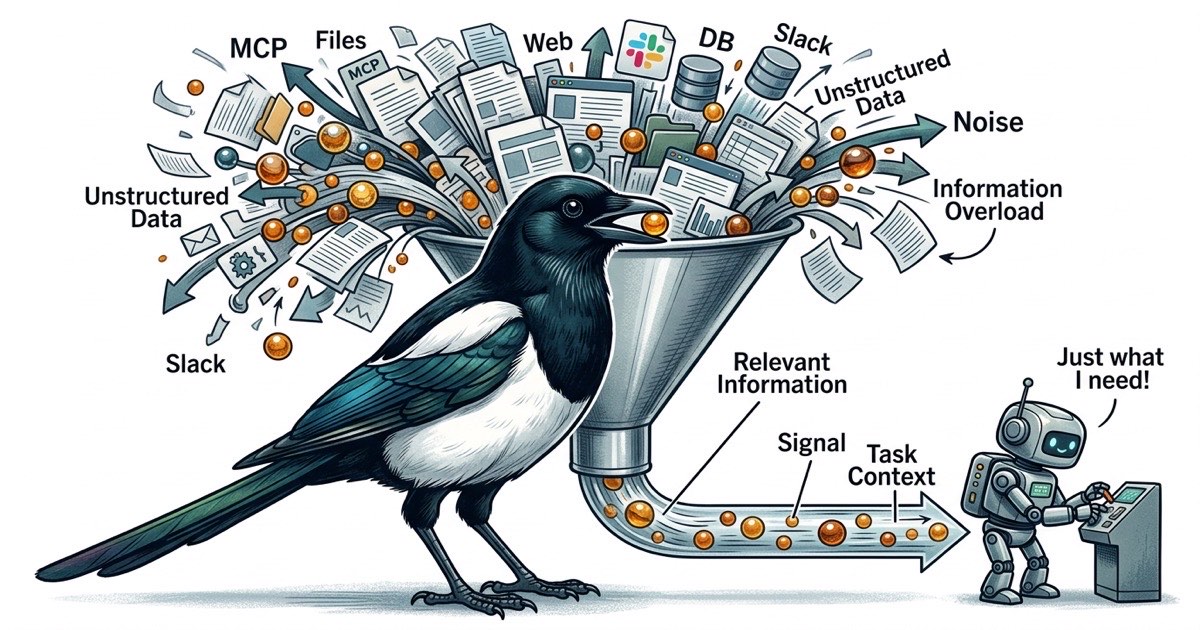
6つのMCPサーバー。それぞれがエージェントのコンテキストにツールスキーマを登録します。それぞれがエージェントができることの表面積を広げ、ツール説明に費やすトークンが増え、エージェントが本題から逸れる機会が増えます。
エージェントはまだ良いコードを書いています。しかし書くのが遅くなり、出力の予測可能性が下がりました。気のせいではありません。コンテキストウィンドウがボトルネックになっていて、それを配管で埋めているのです。
蓄積の問題
MCPサーバーは強力です。Model Context ProtocolはClaude Codeに外部システムへのアクセスを与え、各統合は本当に問題を解決します。ファイルアクセスでエージェントはコードベースを読めます。ウェブ検索でドキュメントを調べられます。GitHub統合でPRのステータスを確認できます。
問題は、エージェントのあらゆるニーズを別のMCPを追加することで解決し始めるときに始まります。
エージェントがデータベーススキーマを確認する必要がある?Postgres MCPを追加。エージェントがConfluenceページを読む必要がある?Confluence MCPを追加。エージェントがSlackメッセージを投稿する必要がある?Slack MCPを追加。個別にはどれも正当化できます。しかし合わせると、出力品質が落ちるまで気づきにくい問題を生み出します。
各MCPサーバーは会話コンテキストにツールを登録します。ファイルアクセスMCPは5〜10個のツールを登録するかもしれません。データベースMCPがさらに数個。GitHub MCPがさらに追加。6つのMCPサーバーがあると、エージェントはコードの1行目を読む前に、コンテキストウィンドウに数十個のツール定義を抱えています。
これらのツール定義は無料ではありません。トークンを消費します。そしてさらに重要なのは、エージェントの注意力を奪い合うということです。エージェントに40個のツールがある場合、あらゆる判断ポイントが分岐する質問になります:ファイルツールを使うべきか、検索ツールか、データベースツールか、GitHubツールか?エージェントは問題を解決するために情報を使うのではなく、情報を取得する方法を決めるのに認知予算を使います。
コンテキストは有限。注意力はもっと希少。
Claude Codeのコンテキストウィンドウは大きいです。これが危険な錯覚を生みます:結果なしに情報を追加し続けられるという錯覚です。
実際には、エージェントのパフォーマンスはコンテキストウィンドウが埋まるずっと前に劣化します。問題は容量ではありません。信号対雑音比です。200Kトークンのコンテキストウィンドウを持つエージェントは、関連するビットがツールスキーマ、APIレスポンス、関係のないファイル内容に散在する150Kトークンよりも、集中した関連情報50Kトークンの方がうまく機能します。
ブラウザのタブが多すぎるときに人間が直面するのと同じ問題です。情報は技術的には利用可能です。見つけるのに必要以上に時間がかかります。関連するコンテキストがノイズによって作業記憶から押し出されたため、既に見たものを読み直すことになります。
エージェントでは、これは以下のように現れます:
ウサギの穴。 エージェントにデータベースツールがあるので、スキーマをクエリします。スキーマが興味深いので、データをクエリします。データに予想外のものが見つかったので、さらに調査します。20分後、データベース内容の徹底的な分析ができましたが、依頼した機能の進捗はゼロです。
ツールの混乱。 多くのツールが利用可能な場合、エージェントは時々間違ったものを選びます。ローカルファイルに既にあるドキュメントをウェブ検索で探します。タスク説明に答えがあるのにデータベースをクエリします。間違ったツール選択のたびにトークンが無駄になり、ノイズが発生します。
希薄なフォーカス。 エージェントの「注意力」は各生成内の有限リソースです。コンテキストにファイルアクセス、ウェブ検索、データベースクエリ、GitHub操作、Slackメッセージ、Wiki検索のツールスキーマが含まれていると、エージェントは実際のリクエストを処理する前にそれらすべてを処理します。タスクはツールと認知的優先度を奪い合います。
境界付きコンテキスト:ツール肥大化の代替案
「エージェントが情報Xを必要としている」に対する反射的な回答は、Xを取得するツールをエージェントに与えることです。しかし別のアプローチがあります:Xをタスクに入れることです。
これが境界付きコンテキストパターンです。エージェントにすべてへのアクセスを与えて関連するものを見つけることを期待するのではなく、各エージェントに作業を完了するために必要なすべてを含むタスクを与えます。エージェントはコンテキストを探しません。コンテキストが届けられます。
違いは構造的なものです。MCPの肥大化がある場合、エージェントのワークフローは:
- タスクを読む
- 不足している情報を把握する
- 様々なツールを使ってその情報を収集する
- 情報を統合する
- 実際の作業を行う
境界付きコンテキストでは:
- タスクを読む(必要なコンテキストがすべて含まれている)
- 実際の作業を行う
最初のワークフローのステップ2〜4は単なるオーバーヘッドではありません。物事がうまくいかなくなるのはそこです。エージェントが情報を集めすぎたり、間違った情報を集めたり、興味深いが無関係なデータに気を取られたりします。ツール呼び出しの一つ一つが潜在的な寄り道です。
境界付きコンテキストはエージェントがツールを使えないということではありません。ファイルアクセスはコードの読み書きに引き続き必要です。しかし情報的コンテキスト(何を構築するか、なぜ、どのファイル、受け入れ基準は何か)はタスクの中に存在し、エージェントがクエリしなければならないツールの中にはないということです。
タスクをコンテキストコンテナとして構造化する
コンテキストコンテナとして機能するタスクは、典型的なJiraチケットやGitHub Issueとは異なります。自己完結しています。それを読むエージェントは、外部システムに背景情報を問い合わせることなく、作業を開始するために必要なすべてを持っているべきです。
実際にはこのようになります:
Title: Add rate limiting to /api/search endpoint
Description:
The /api/search endpoint currently has no rate limiting.
Add a token bucket rate limiter at 100 requests/minute per IP.
Files to modify:
- server/middleware/rate-limit.ts (create new)
- server/routes/search.ts (apply middleware)
- server/config.ts (add RATE_LIMIT_RPM env var)
Acceptance criteria:
- Requests beyond 100/min from same IP return 429
- Rate limit resets after 60 seconds
- Config value overridable via environment variable
- Existing tests still pass
Context:
- We use Express middleware pattern (see server/middleware/auth.ts for example)
- The config module uses dotenv (see server/config.ts lines 1-15)
- No Redis available; use in-memory store. This is a single-instance app.
Dependencies: None. This can run independently.
タスクに何が埋め込まれているか注目してください。エージェントはどのファイルに触れるか、どのパターンに従うか、どの制約があるか(Redisなし)、「完了」が正確にどう見えるかを知っています。スキーマを確認するためのデータベースMCPは不要です。ミドルウェアパターンを見つけるためのWikiツールも不要です。設定アプローチを理解するためにコードベースを検索する必要もありません。すべてがタスクにあります。
このようにタスクを書くには前もって多くの努力が必要です。典型的なチケットは「検索エンドポイントにレート制限を追加」と言って、残りはエージェントに任せるかもしれません。しかしその「解明」プロセスこそがMCP肥大化の原因です:エージェントが情報を必要とするのでツールを与え、ツールがコンテキストを食います。