आपने जितने भी issue trackers use किए हैं, सब same pattern follow करते हैं। एक cloud service है। उसका web UI है। किसी ने CLI बनाई जो cloud API से बात करती है। CLI second-class citizen है: धीमी, कम capable, हमेशा एक API version पीछे।
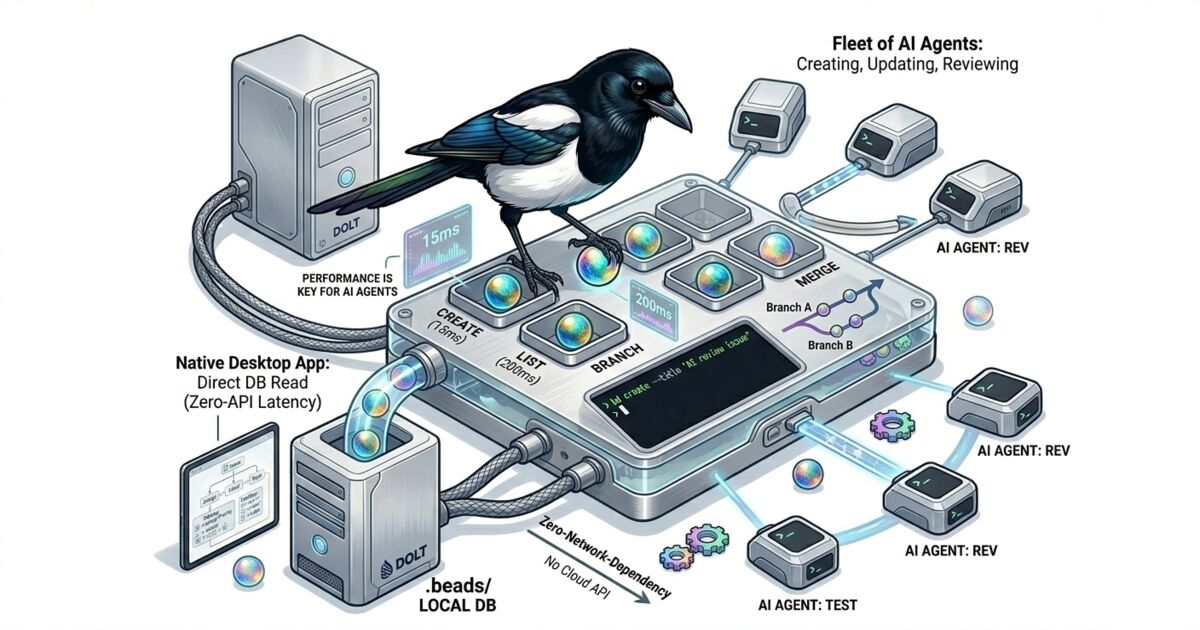
अब यह architecture उलट दें। CLI से शुरू करें। Local database में write कराएँ। Database को version-controlled बनाएँ, वही branching और merging semantics जो source code पर use करते हैं। फिर ऊपर native desktop app रखें जो सीधे वही database files read करे, बीच में कोई API नहीं।
यही beads और Beadbox करते हैं। और यह architecture AI agents की वजह से exist करता है।
Problem: agents buttons click नहीं कर सकते
अगर AI agents का fleet coordinate कर रहे हैं (code generators, reviewers, testers, deployers), उन्हें issues create करने, statuses update करने, और work queues read करने की ज़रूरत है। वे Jira को authenticate नहीं कर सकते। Linear का UI navigate नहीं कर सकते। उन्हें CLI चाहिए जो local database में write करे, fast, zero network dependencies।
beads वही CLI है। Open-source, Git-native issue tracker जो ठीक इसी workflow के लिए designed है। bd command issues create, update, list, और close करता है। हर write आपके repository की .beads/ directory में local Dolt database में land होता है।
Numbers matter करते हैं। bd create करीब 15ms लेता है। bd list 10,000 issues पर करीब 200ms में return करता है। ये benchmarks beads test suite से हैं। जब agents tight loops में work items process कर रहे हैं, per operation milliseconds decide करते हैं कि issue tracker साथ रह पाता है या bottleneck बन जाता है।
Dolt क्यों, SQLite नहीं?
Dolt एक SQL database है जो Git semantics implement करता है। हर write एक commit है। दो points के बीच क्या बदला देखने के लिए dolt diff। Full audit history के लिए dolt log। dolt branch और dolt merge उसी mental model से जो code पर already use करते हैं।
Issue tracking के लिए, इसका मतलब project history में दो parallel audit trails: code changes के लिए git log, issue changes के लिए dolt log। सवालों का जवाब दे सकते हैं जैसे "v2.1.0 tag करते समय issue database कैसा दिखता था?" बस Dolt history में वह point checkout करके। Issue database branch करके reorganization experiment कर सकते हैं, फिर merge back करें या throw away।
beads ने v0.9.0 में SQLite support remove करके पूरी तरह Dolt पर shift किया। Version control semantics nice-to-have नहीं; foundation हैं। जब बीस agents एक ही issue database में write कर रहे हैं, उस data को diff, branch, और merge करने की ability चाहिए उसी confidence से जो source control पर है।
Optional collaboration DoltHub से काम करती है। Issue database remote पर push करें, teammates से changes pull करें। Git जैसा ही push/pull workflow, structured data पर apply।
Visual layer: Beadbox
Agents CLIs से अच्छे से काम करते हैं। Humans नहीं, कम से कम जब big picture चाहिए। Dependency graphs, epic progress trees, blocked-issue chains: ये spatial problems हैं जो terminal अच्छे से render नहीं कर सकता।
Beadbox Tauri (Electron नहीं) से बना native desktop application है जो वही .beads/ directory read करता है जिसमें CLI write करती है। कोई import step नहीं, sync process नहीं, API layer नहीं। GUI fs.watch() से filesystem watch करता है, Dolt database changes detect करता है, और local WebSocket से updates broadcast करता है। जब agent bd update BEAD-42 --status in_progress run करता है, Beadbox में status badge milliseconds में बदलता है।
Practice में workflow कैसा दिखता है:
# एक agent issue create करता है
bd create --title "Migrate auth to OIDC" --type task --priority 1
# दूसरा agent claim करता है
bd update BEAD-42 --claim --actor agent-3
# Human Beadbox खोलता है और full board देखता है:
# dependency graphs, epic trees, status/priority/assignee से filter
# कोई commands नहीं। बस देखो।
# Agent finish करता है और review के लिए mark करता है
bd update BEAD-42 --status ready_for_qa
# Beadbox real time में update होता है। QA agent pick करता है।
Agents CLI से write करते हैं। Humans GUI से read करते हैं। दोनों एक ही local Dolt database operate करते हैं। कोई reconciliation नहीं, stale caches नहीं, "refresh करने दो" नहीं।
Beadbox macOS, Linux, और Windows पर चलता है। Multiple workspaces support करता है, restart किए बिना projects switch कर सकते हैं।
"Local-first" का actually मतलब क्या है
Term overuse होता है। beads और Beadbox के लिए concrete में इसका मतलब:
कोई account नहीं। किसी चीज़ के लिए sign up नहीं करना। CLI install करें, app install करें, directory पर point करें। बस।
Cloud dependency नहीं। सब कुछ filesystem पर चलता है। Data कभी machine नहीं छोड़ता जब तक explicitly dolt push to remote न करें। Internet down? कुछ नहीं बदलता। काम करते रहो।
Server नहीं। कोई daemon manage करने को नहीं, Docker container run करने को नहीं। Dolt database files की directory है। CLI उन files read और write करती है। Beadbox उन files watch करता है।
Optional collaboration। जब share करना हो, DoltHub पर push करें। Teammates pull करें। Issue data पर merge conflicts वैसे ही resolve होते हैं जैसे code पर। पर यह opt-in है, required नहीं।
Alternatives से compare करें। Jira को server चाहिए (या Atlassian Cloud)। Linear को account और internet connection चाहिए। GitHub Issues को GitHub servers पर repository चाहिए। Self-hosted options जैसे Gitea को भी web service चलानी पड़ती है।
beads को एक directory चाहिए। Beadbox को वही directory और एक double-click।
यह किसके लिए है
अगर AI agents run करते हैं जिन्हें shared work queue से coordinate करना है, और humans को visually उस काम को monitor और steer करना है, यह stack आपके workflow के लिए बना है।
अगर solo projects manage करते हैं और version-controlled issue tracking चाहते हैं जो code के बगल में रहे, बिना cloud account, यह stack उसके लिए भी काम करता है।
अगर Jira का enterprise permission model या Linear का distributed team real-time collaborative editing चाहिए, यह सही tool नहीं। beads design से local-first है। यह tradeoff है, oversight नहीं।
शुरू करें
beads CLI github.com/steveyegge/beads से install करें, फिर Beadbox:
brew tap beadbox/cask && brew install --cask beadbox
किसी भी project में beads database initialize करें:
cd your-project
bd init
Beadbox खोलें, उस directory पर point करें, issue board देख रहे होंगे। कोई signup नहीं। कोई configuration wizard नहीं। कोई "connect your GitHub account" modal नहीं।
Beadbox beta में free है।