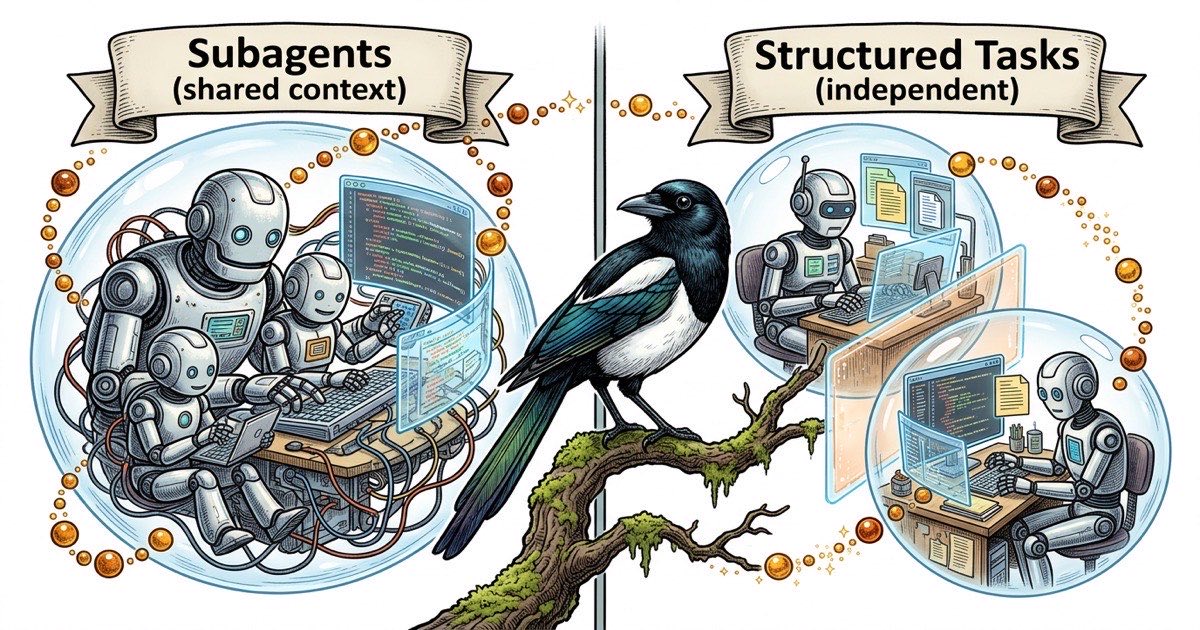
Aapke paas ek feature hai jismein teen cheezein ek saath karni hain. Aap ek single Claude Code session ke andar subagents spawn kar sakte hain aur unhe parallel kaam karne de sakte hain. Ya phir aap kaam ko teen independent tasks mein tod sakte hain, har ek ko alag agent ko uske apne tmux pane mein de sakte hain, aur unhe ek doosre ke baare mein bina jaane chalne de sakte hain.
Dono approaches kaam ko parallelize karti hain. Ve alag problems solve karti hain. Galat chunein aur ya to aap context window coordination overhead mein jalaa denge ya phir merge conflicts create kar denge jo original task se zyada time lete hain fix hone mein.
Yeh woh decision framework hai jo main har roz use karta hoon jab 13 Claude Code agents ek hi codebase par chalata hoon. Yeh theoretical nahi hai. Yeh itni baar galat karne ka result hai ki ab pata hai boundary kahaan hai.
Do tarah ka parallelism
Claude Code do alag tarike se concurrent kaam support karta hai.
Subagents child processes hain jo ek single Claude Code session ke andar spawn hote hain. Parent agent multiple subagents launch karta hai, har ek problem ka ek hissa handle karta hai, phir results collect karta hai. Ve same working directory aur parent ka context share karte hain. Inhe ek single process mein threads samjhein.
Parent agent
├── Subagent A: "Search lib/ for all usages of parseConfig"
├── Subagent B: "Search server/ for all usages of parseConfig"
└── Subagent C: "Search components/ for all usages of parseConfig"
Separate agents independent Claude Code sessions mein chalte hain, typically alag tmux panes mein. Har ek ki apni context window, apni CLAUDE.md identity file, aur codebase ki apni view hoti hai. Ve memory share nahi karte. Ve artifacts ke through communicate karte hain: task comments, status updates, committed code. Inhe alag processes samjhein jinka koi shared state nahi hai.
tmux pane 1: eng1 agent → "Build the REST endpoint"
tmux pane 2: eng2 agent → "Build the React component"
tmux pane 3: qa1 agent → "Write integration tests for both"
Mental model zaroori hai kyunki yeh determine karta hai ki kaam units ke beech kaise flow karta hai. Subagents data parent ko cheaply pass kar sakte hain. Separate agents data filesystem, git, ya external task tracker ke through pass karte hain.
Subagents kab jeette hain
Subagents tab use karein jab kaam state share karta ho aur results ko converge hona ho.
Parallel research. Aapko paanch directories mein ek pattern search karna hai, teen documentation files padhni hain, aur findings ko ek recommendation mein synthesize karna hai. Subagents har ek search path le sakte hain, results return kar sakte hain, aur parent unhe bina serialization overhead ke combine kar sakta hai.
Same data par independent transformations. Aap ek module refactor kar rahe hain aur type definitions, tests, aur documentation ko ek coherent change mein update karna hai. Har subagent ek file handle karta hai, lekin parent ensure karta hai ki changes consistent hain kyunki woh commit karne se pehle teeno results dekhta hai.
Fast exploration. Aap debug kar rahe hain aur simultaneously git log, test output, aur runtime config check karni hai. Subagents teeno parallel gather kar sakte hain aur parent diagnosis synthesize karta hai.
Pattern: fan out, gather back, combined result par act karein. Agar aapka parallelism is par khatam hota hai ki parent ko saare outputs ke baare mein saath mein reason karna hai, to subagents sahi tool hain.
Subagents kismein bure hain: koi bhi cheez jo per branch kuch minutes se zyada le, koi bhi cheez jo overlapping paths mein files modify kare, ya koi bhi cheez jisko independent verification chahiye. Subagents working directory share karte hain, to do subagents same file mein likhenge to ek doosre ka kaam corrupt kar denge. Aur kyunki ve context share karte hain, ek long-running subagent parent ki available window khaa leta hai.
Separate agents kab jeette hain
Separate agents tab use karein jab kaam independently verify ho sake aur use make sense ke liye shared context ki zaroorat na ho.
Same feature ke alag components. "API endpoint banao" aur "Frontend banao jo use call kare" integration tak independent hain. API engineer ko React component context mein nahi chahiye. Frontend engineer ko database schema nahi chahiye. Har ek ko apna agent dena ek scoped CLAUDE.md ke saath context clean rakhta hai aur ek agent ki complexity ko doosre ke kaam mein bleed hone se rokta hai.
Alag acceptance criteria. Agar task A tab done hai jab endpoint 200 return kare correct JSON shape ke saath, aur task B tab done hai jab component data ko proper error states ke saath render kare, to ve alag verification targets hain. QA agent har ek ko independently validate kar sakta hai. Subagents independently QA nahi ho sakte kyunki ve ek combined output produce karte hain.
Kaam jo codebase ke alag parts touch karta hai. File ownership merge conflicts rokne ka sabse simple tarika hai. Agent A server/ ka maalik hai, Agent B components/ ka. Koi bhi doosre ke territory mein nahi jaata. Agar aap yeh subagents ke saath try karein, to parent ko file locking manage karni padegi, jo parallelism ka purpose hi defeat kar deta hai.
Alag time horizons wale tasks. Ek task 10 minute leta hai, doosra 2 ghante. Subagents ke saath, parent sabse slow child ka wait karta hai. Separate agents ke saath, short task complete hota hai, verify hota hai, aur ship hota hai jabki long task abhi bhi chal raha hai.
Pattern: fire, forget, separately verify karein. Agar kaam ka har piece akele khada ho sake aur akele check ho sake, to structured tasks ke saath separate agents zyada clean hain.
Handoff ka problem
Asli decision point handoffs par aata hai.
Subagent handoffs cheap hain. Child same context mein parent ko data return karta hai. Koi serialization nahi, koi file writes nahi, koi status update ka wait nahi. Parent teen subagents launch karta hai, ve teen results return karte hain, parent ke paas sab kuch hai.
Separate agent handoffs expensive hain lekin durable. Agent A kaam complete karta hai, code commit karta hai, task status update karta hai, aur comment karta hai kya kiya. Agent B woh signal pick up karta hai (ya to coordinator ke through ya task tracker ko poll karke) aur apna dependent kaam shuru karta hai. Overhead real hai: aapko task system chahiye, status protocol chahiye, aur agents ke liye koi tarika chahiye doosre agents ne kya kiya yeh discover karne ka.
Rule of thumb: agar kaam mein parallel units ke beech ek se zyada handoff chahiye, subagents use karein. Single fan-out-and-gather ke liye subagents simpler hain. Agar Agent A ka output Agent B ka input hai, jo Agent C ka input banta hai, to separate agents ki coordination cost justified hai kyunki har handoff ek verified, committed artifact produce karta hai jo lost nahi hoga agar agent crash ho ya context limit hit kare.
Ek concrete example. Aapko:
- Saare API endpoints dhundhne hain jo user data return karte hain
- Har ek mein rate limiting add karni hai
- Naye rate limits ke liye tests likhne hain
- API documentation update karni hai
Steps 1 aur 2 tightly coupled hain. Search results (step 1) directly modification mein feed karte hain (step 2). Ek subagent search handle karta hai; parent changes apply karta hai. Yeh subagent pattern hai.
Steps 3 aur 4 ek doosre se independent hain lekin step 2 par depend karte hain. Tests ko actual endpoint code chahiye. Docs ko final API shape chahiye. Yeh separate agents ke liye separate tasks hain, har ek ke apne acceptance criteria, har ek apne aap verifiable.