आपने एक MCP सर्वर से शुरुआत की। फ़ाइल एक्सेस, ताकि आपका Claude Code एजेंट आपका प्रोजेक्ट पढ़ और लिख सके। उचित था।
फिर आपने वेब सर्च जोड़ा। फिर GitHub। फिर एक डेटाबेस टूल ताकि एजेंट सीधे आपका schema क्वेरी कर सके। फिर Slack, क्योंकि एजेंट को requirements के लिए एक थ्रेड चेक करना था। फिर आपके इंटरनल wiki के लिए एक डॉक्स टूल।
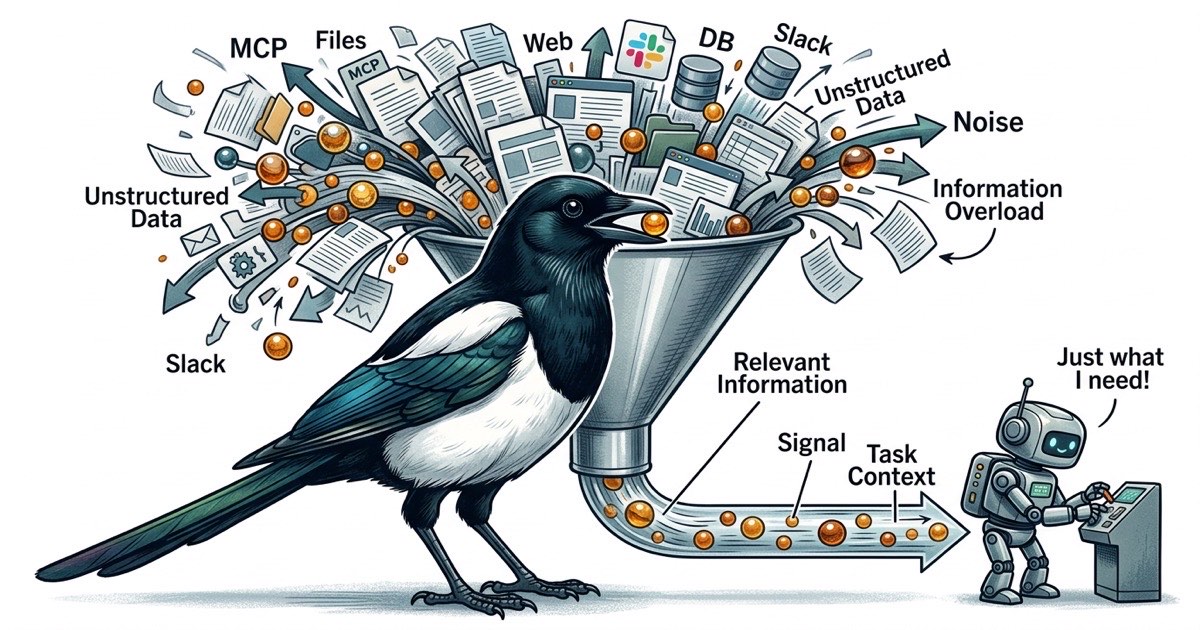
छह MCP सर्वर। हर एक एजेंट के कॉन्टेक्स्ट में टूल schemas रजिस्टर करता है। हर एक उस सतह क्षेत्र को बढ़ाता है जो एजेंट कर सकता है, जिसका मतलब है टूल विवरणों पर अधिक tokens खर्च होना और एजेंट के कार्य से भटकने के अधिक अवसर।
आपका एजेंट अभी भी अच्छा कोड लिखता है। लेकिन धीमे लिखता है, और आउटपुट कम पूर्वानुमेय हो गया है। आप कल्पना नहीं कर रहे। कॉन्टेक्स्ट विंडो बॉटलनेक है, और आप इसे प्लंबिंग से भर रहे हैं।
संचय की समस्या
MCP सर्वर शक्तिशाली हैं। Model Context Protocol Claude Code को बाहरी सिस्टम तक पहुंच देता है, और हर integration वास्तव में एक समस्या हल करता है। फ़ाइल एक्सेस एजेंट को आपका कोडबेस पढ़ने देता है। वेब सर्च उसे documentation देखने देता है। GitHub integration उसे PR स्टेटस चेक करने देता है।
समस्या तब शुरू होती है जब आप एजेंट की हर ज़रूरत को एक और MCP जोड़कर हल करते हैं।
एजेंट को डेटाबेस schema चेक करना है? Postgres MCP जोड़ो। एजेंट को Confluence पेज पढ़ना है? Confluence MCP जोड़ो। एजेंट को Slack मैसेज पोस्ट करना है? Slack MCP जोड़ो। हर एक अलग से उचित है। मिलकर, वे एक ऐसी समस्या पैदा करते हैं जो आउटपुट क्वालिटी गिरने तक नज़र नहीं आती।
हर MCP सर्वर conversation कॉन्टेक्स्ट में अपने टूल्स रजिस्टर करता है। एक फ़ाइल एक्सेस MCP 5-10 टूल्स रजिस्टर कर सकता है। एक डेटाबेस MCP और कुछ। एक GitHub MCP और जोड़ता है। जब आपके पास छह MCP सर्वर होते हैं, तो एजेंट आपके कोड की एक भी लाइन पढ़ने से पहले अपनी कॉन्टेक्स्ट विंडो में दर्जनों टूल definitions लिए होता है।
ये टूल definitions मुफ़्त नहीं हैं। वे tokens खाते हैं। और इससे भी महत्वपूर्ण बात, वे एजेंट के ध्यान के लिए प्रतिस्पर्धा करते हैं। जब एक एजेंट के पास 40 उपलब्ध टूल्स होते हैं, तो हर निर्णय बिंदु एक शाखाबद्ध प्रश्न बन जाता है: क्या मुझे फ़ाइल टूल, सर्च टूल, डेटाबेस टूल, या GitHub टूल का उपयोग करना चाहिए? एजेंट अपनी समस्या हल करने के लिए जानकारी इस्तेमाल करने के बजाय जानकारी कैसे प्राप्त करें यह तय करने पर cognitive बजट खर्च करता है।
कॉन्टेक्स्ट सीमित है। ध्यान और भी दुर्लभ है।
Claude Code की कॉन्टेक्स्ट विंडो बड़ी है। यह एक खतरनाक भ्रम पैदा करता है: कि आप बिना परिणाम के जानकारी जोड़ते रह सकते हैं।
व्यवहार में, कॉन्टेक्स्ट विंडो भरने से बहुत पहले एजेंट का प्रदर्शन गिरने लगता है। मुद्दा क्षमता नहीं है। सिग्नल-टू-नॉइज़ अनुपात है। 200K token कॉन्टेक्स्ट विंडो वाला एजेंट 50K tokens की केंद्रित, प्रासंगिक जानकारी के साथ बेहतर काम करता है बनिस्बत 150K tokens जहां प्रासंगिक हिस्से टूल schemas, API responses, और असंबद्ध फ़ाइल सामग्री के बीच बिखरे हैं।
यह वही समस्या है जो मनुष्य बहुत सारे ब्राउज़र टैब्स के साथ झेलते हैं। जानकारी तकनीकी रूप से उपलब्ध है। उसे ढूंढने में ज़रूरत से ज़्यादा समय लगता है। आप पहले से देखी हुई चीज़ें दोबारा पढ़ते हैं क्योंकि प्रासंगिक कॉन्टेक्स्ट शोर द्वारा कार्यशील स्मृति से बाहर धकेल दिया गया।
एजेंट्स के लिए, यह इस रूप में प्रकट होता है:
खरगोश के बिल। एजेंट के पास डेटाबेस टूल है, तो वह schema क्वेरी करता है। Schema दिलचस्प है, तो वह डेटा क्वेरी करता है। डेटा कुछ अप्रत्याशित दिखाता है, तो वह और जांच करता है। बीस मिनट बाद, आपके पास अपने डेटाबेस सामग्री का गहन विश्लेषण है और आपके मांगे हुए feature पर शून्य प्रगति।
टूल भ्रम। कई उपलब्ध टूल्स के साथ, एजेंट कभी-कभी गलत चुनता है। स्थानीय फ़ाइल में पहले से मौजूद documentation ढूंढने के लिए वेब सर्च का उपयोग करता है। जब उत्तर कार्य विवरण में है तब डेटाबेस क्वेरी करता है। हर गलत टूल चुनाव tokens बर्बाद करता है और शोर लाता है।
पतला फोकस। एजेंट का "ध्यान" हर generation में एक सीमित संसाधन है। जब कॉन्टेक्स्ट में फ़ाइल एक्सेस, वेब सर्च, डेटाबेस क्वेरी, GitHub ऑपरेशंस, Slack मैसेज, और Wiki lookups के टूल schemas होते हैं, तो एजेंट आपके वास्तविक अनुरोध को प्रोसेस करने से पहले यह सब प्रोसेस करता है। कार्य, टूलिंग के साथ cognitive प्राथमिकता के लिए प्रतिस्पर्धा करता है।
सीमित कॉन्टेक्स्ट: टूल बिखराव का विकल्प
"मेरे एजेंट को जानकारी X चाहिए" का प्रतिक्रियात्मक उत्तर है एजेंट को X लाने वाला टूल देना। लेकिन एक और तरीका है: X को कार्य में डालना।
यह सीमित कॉन्टेक्स्ट पैटर्न है। एजेंट्स को सबकुछ तक पहुंच देने और उम्मीद करने कि वे प्रासंगिक चीज़ पाएंगे, इसके बजाय आप हर एजेंट को एक कार्य देते हैं जिसमें काम पूरा करने के लिए ज़रूरी सबकुछ है। एजेंट कॉन्टेक्स्ट नहीं खोजता। कॉन्टेक्स्ट पहुंचाया जाता है।
अंतर संरचनात्मक है। MCP बिखराव के साथ, एजेंट का workflow ऐसा दिखता है:
- कार्य पढ़ो
- पता लगाओ कौन सी जानकारी गायब है
- विभिन्न टूल्स का उपयोग करके वह जानकारी इकट्ठा करो
- जानकारी को संश्लेषित करो
- वास्तविक काम करो
सीमित कॉन्टेक्स्ट के साथ, ऐसा दिखता है:
- कार्य पढ़ो (जिसमें सारा ज़रूरी कॉन्टेक्स्ट है)
- वास्तविक काम करो
पहले workflow में चरण 2-4 सिर्फ़ overhead नहीं हैं। वहीं चीज़ें गलत होती हैं। एजेंट बहुत ज़्यादा जानकारी इकट्ठा करता है, या गलत जानकारी, या दिलचस्प लेकिन अप्रासंगिक डेटा से विचलित होता है। हर टूल invocation एक संभावित चक्कर है।
सीमित कॉन्टेक्स्ट का मतलब यह नहीं कि एजेंट टूल्स का उपयोग नहीं कर सकते। फ़ाइल एक्सेस कोड पढ़ने और लिखने के लिए अभी भी ज़रूरी है। लेकिन इसका मतलब है कि सूचनात्मक कॉन्टेक्स्ट (क्या बनाना है, क्यों, कौन सी फ़ाइलें, acceptance criteria क्या हैं) कार्य में रहता है, उस टूल में नहीं जिसे एजेंट को क्वेरी करना पड़े।
कार्यों को कॉन्टेक्स्ट कंटेनर के रूप में संरचित करना
कॉन्टेक्स्ट कंटेनर के रूप में काम करने वाला कार्य एक सामान्य Jira टिकट या GitHub issue से अलग दिखता है। यह स्व-निहित है। इसे पढ़ने वाले एजेंट के पास बैकग्राउंड जानकारी के लिए बाहरी सिस्टम से पूछे बिना काम शुरू करने के लिए सबकुछ होना चाहिए।
व्यवहार में यह ऐसा दिखता है:
Title: Add rate limiting to /api/search endpoint
Description:
The /api/search endpoint currently has no rate limiting.
Add a token bucket rate limiter at 100 requests/minute per IP.
Files to modify:
- server/middleware/rate-limit.ts (create new)
- server/routes/search.ts (apply middleware)
- server/config.ts (add RATE_LIMIT_RPM env var)
Acceptance criteria:
- Requests beyond 100/min from same IP return 429
- Rate limit resets after 60 seconds
- Config value overridable via environment variable
- Existing tests still pass
Context:
- We use Express middleware pattern (see server/middleware/auth.ts for example)
- The config module uses dotenv (see server/config.ts lines 1-15)
- No Redis available; use in-memory store. This is a single-instance app.
Dependencies: None. This can run independently.
ध्यान दें कार्य में क्या embedded है। एजेंट जानता है किन फ़ाइलों को छूना है, किस pattern का पालन करना है, कौन सी बाधाएं हैं (कोई Redis नहीं), और "पूर्ण" ठीक कैसा दिखता है। उसे schema चेक करने के लिए डेटाबेस MCP नहीं चाहिए। उसे middleware pattern ढूंढने के लिए wiki टूल नहीं चाहिए। उसे config दृष्टिकोण समझने के लिए कोडबेस खोजने की ज़रूरत नहीं। सबकुछ कार्य में है।
इस तरह कार्य लिखना शुरू में अधिक प्रयास मांगता है। एक सामान्य टिकट कह सकता है "search endpoint में rate limiting जोड़ो" और बाकी एजेंट पर छोड़ सकता है। लेकिन वह "पता लगाने" की प्रक्रिया ठीक वही है जहां से MCP बिखराव आता है: एजेंट को जानकारी चाहिए, तो आप उसे टूल्स देते हैं, और टूल्स कॉन्टेक्स्ट खाते हैं।