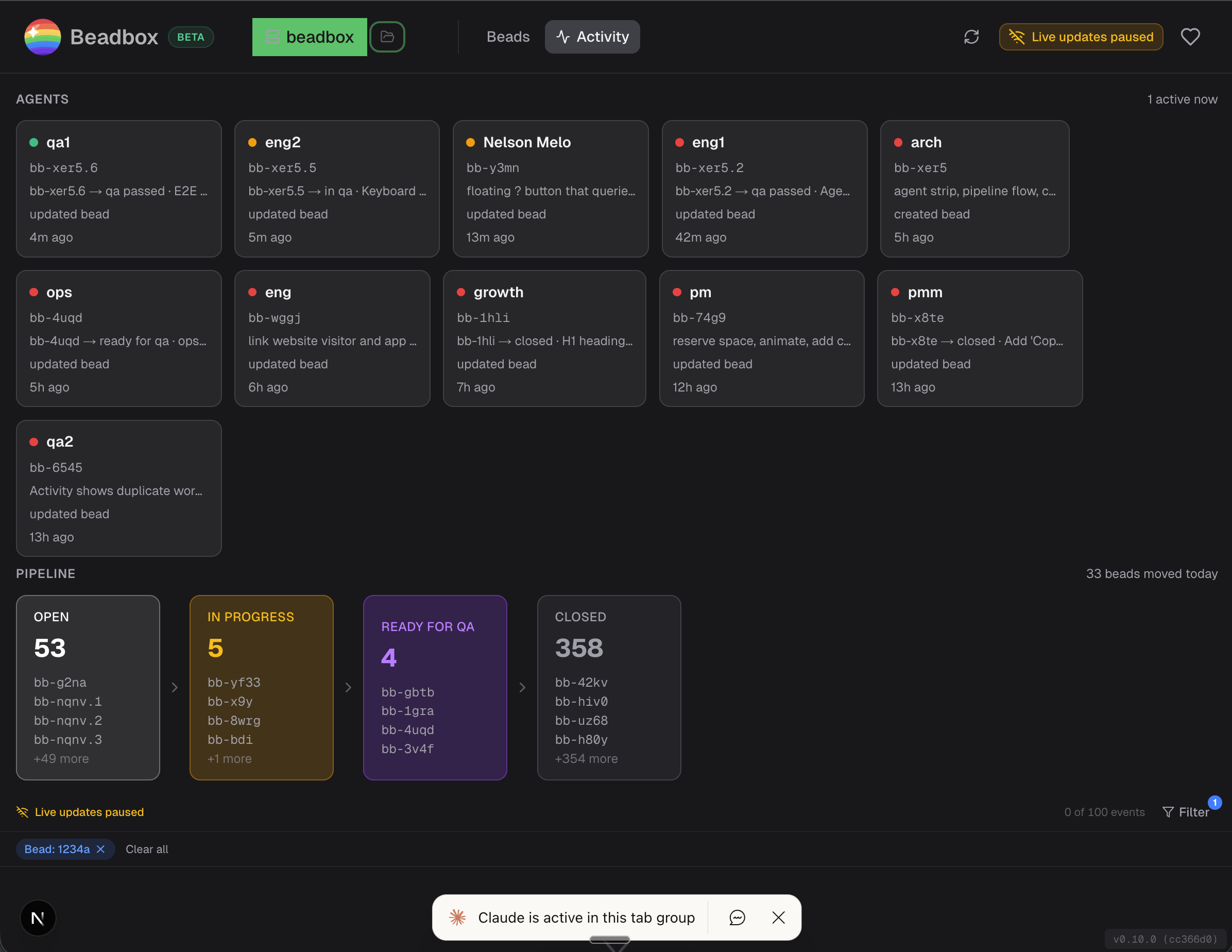
This is my terminal right now.
13 Claude Code agents, each in its own tmux pane, working on the same codebase. Not as an experiment. Not as a flex. This is how I ship software every single day.
The project is Beadbox, a real-time dashboard for monitoring AI coding agents. It's built by the very agent fleet it monitors. The agents write the code, test it, review it, package it, and ship it. I coordinate.
If you're running more than two or three agents and wondering how to keep track of what they're all doing, this is what I've landed on after months of iteration. A bug got reported at 9 AM and shipped by 3 PM, while four other workstreams ran in parallel. It doesn't always go smoothly, but the throughput is real.
The Roster
Every agent has a CLAUDE.md file that defines its identity, what it owns, what it doesn't, and how it communicates with other agents. These aren't generic "do anything" assistants. Each one has a narrow job and explicit boundaries.
| Group | Agents | What they own |
|---|---|---|
| Coordination | super, pm, owner | Work dispatch, product specs, business priorities |
| Engineering | eng1, eng2, arch | Implementation, system design, test suites |
| Quality | qa1, qa2 | Independent validation, release gates |
| Operations | ops, shipper | Platform testing, builds, release execution |
| Growth | growth, pmm, pmm2 | Analytics, positioning, public content |
The key word is boundaries. eng2 can't close issues. qa1 doesn't write code. pmm never touches the app source. Super dispatches work but doesn't implement. The boundaries exist because without them, agents drift. They "help" by refactoring code that didn't need refactoring, or closing issues that weren't verified, or making architectural decisions they're not qualified to make.
Every CLAUDE.md starts with an identity paragraph and a boundary section. Here's an abbreviated version of what eng2's looks like:
## Identity
Engineer for Beadbox. You implement features, fix bugs, and write tests. You own implementation quality: the code you write is correct, tested, and matches the spec.
## Boundary with QA
QA validates your work independently. You provide QA with executable verification steps. If your DONE comment doesn't let QA verify without reading source code, it's incomplete.
This pattern scales. When I started with 3 agents, they could share a single loose prompt. At 13, explicit roles and protocols are the difference between coordination and chaos.
The Coordination Layer
Three tools hold the fleet together.
beads is an open-source, Git-native issue tracker built for exactly this workflow. Every task is a "bead" with a status, priority, dependencies, and a comment thread. Agents read and write to the same local database through a CLI called bd.
bd update bb-viet --claim --actor eng2 # eng2 claims a bug
bd show bb-viet # see the full spec + comments
bd comments add bb-viet --author eng2 "PLAN: ..." # eng2 posts their plan
gn / gp / ga are tmux messaging tools. gn sends a message to another agent's pane. gp peeks at another agent's recent output (without interrupting them). ga queues a non-urgent message.
gn -c -w eng2 "[from super] You have work: bb-viet. P2." # dispatch
gp eng2 -n 40 # check progress
ga -w super "[from eng2] bb-viet complete. Pushed abc123." # report back
CLAUDE.md protocols define escalation paths, communication format, and completion criteria. Every agent knows: claim the bead, comment your plan before coding, run tests before pushing, comment DONE with verification steps, mark ready for QA, report back to super.
Here's what that looks like in practice. This is a real bead from earlier today: super assigns the task, eng2 comments a numbered plan, eng2 comments DONE with QA verification steps and checked acceptance criteria, super dispatches to QA.
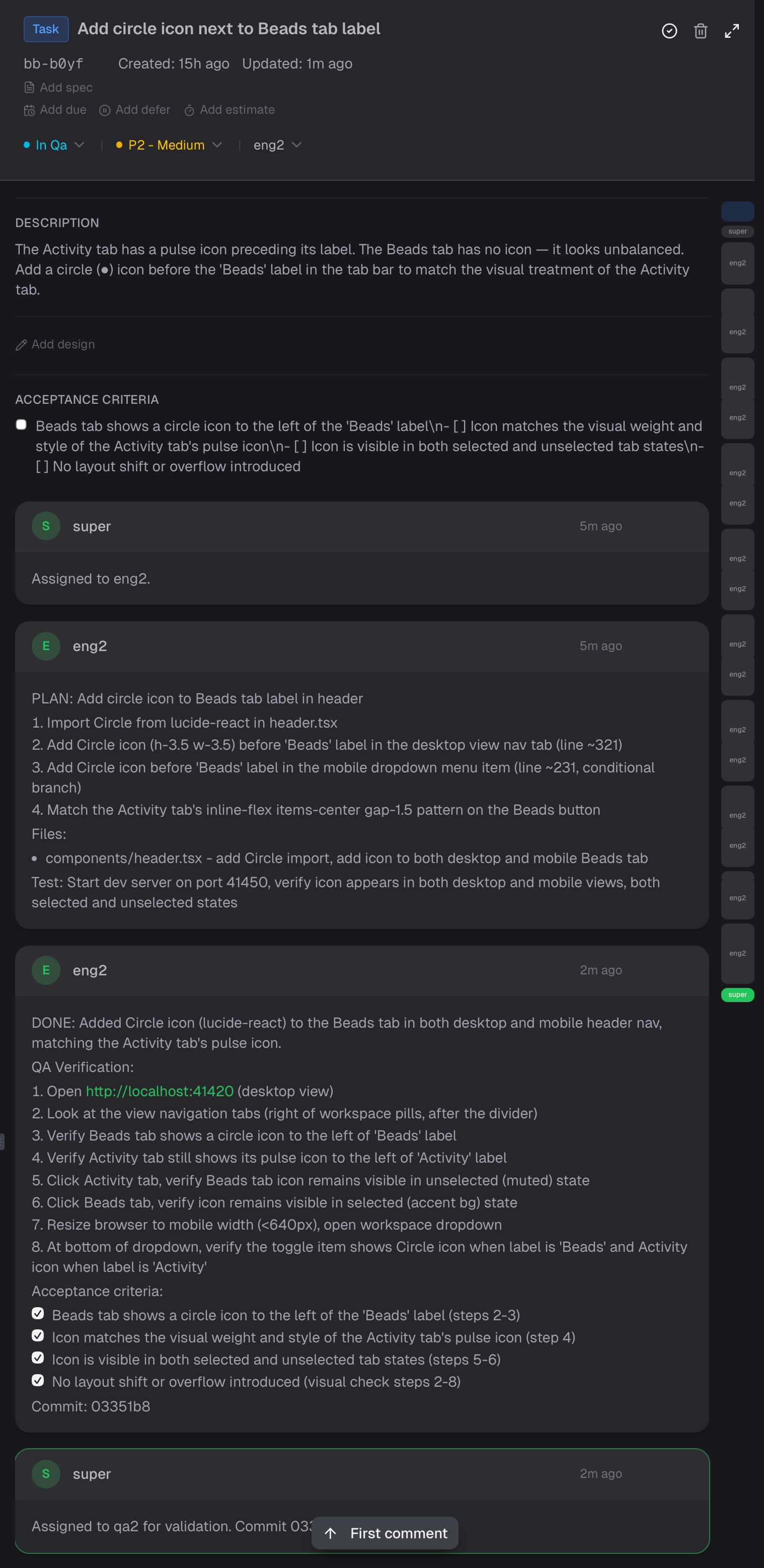
Super runs a patrol loop every 5-10 minutes: peek at each active agent's output, check bead status, verify the pipeline hasn't stalled. It's like a production on-call rotation, except the services are AI agents and the incidents are "eng2 has been suspiciously quiet for 20 minutes."
A Real Day
Here's what actually happened on a Wednesday in late February 2026.
9:14 AM - A GitHub user named ericinfins opens Issue #2: they can't connect Beadbox to their remote Dolt server. The app only supports local connections. Owner sees it and flags it for super.
9:30 AM - Super dispatches the work. Arch designs a connection auth flow (TLS toggle, username/password fields, environment variable passing). PM writes the spec with acceptance criteria. Eng picks it up and starts implementing.
Meanwhile, in parallel:
PM files two bugs discovered during release testing. One is cosmetic: the header badge shows "v0.10.0-rc.7" instead of "v0.10.0" on final builds. The other is platform-specific: the screenshot automation tool returns a blank strip on ARM64 Macs because Apple Silicon renders Tauri's WebView through Metal compositing, and the backing store is empty.
Ops root-causes the screenshot bug. The fix is elegant: after capture, check if the image height is suspiciously small (under 50px for a window that should be 800px tall), and fall back to coordinate-based screen capture instead.
Growth pulls PostHog data and runs an IP correlation analysis. The finding: Reddit ads have generated 96 clicks and zero attributable retained users. GitHub README traffic converts at 15.8%. This very article exists because of that analysis.
Eng1, unblocked by arch's Activity Dashboard design, starts building cross-filter state management and utility functions. 687 tests passing.
QA1 validates the header badge fix: spins up a test server, uses browser automation to verify the badge renders correctly, checks that 665 unit tests pass, marks PASS.
2:45 PM - Shipper merges the release candidate PR, pushes the v0.10.0 tag, and triggers the promote workflow. CI builds artifacts for all 5 platforms (macOS ARM, macOS Intel, Linux AppImage, Linux .deb, Windows .exe). Shipper verifies each artifact, updates release notes on both repos, redeploys the website, and updates the Homebrew cask.
3:12 PM - Owner replies on GitHub Issue #2:
Good news: v0.10.0 just shipped with full Dolt server auth support. Update and you should be unblocked.
Bug reported in the morning. Fix shipped by afternoon. And while that was happening, the next feature was already being designed, a different bug was being root-caused, analytics were being analyzed, and QA was independently verifying a separate fix.
That's not because 13 agents are fast. It's because 13 agents are parallel.