Sie haben mit einem MCP-Server angefangen. Dateizugriff, damit Ihr Claude Code Agent Ihr Projekt lesen und schreiben kann. Vernuenftig.
Dann kam Websuche dazu. Dann GitHub. Dann ein Datenbank-Tool, damit der Agent Ihr Schema direkt abfragen kann. Dann Slack, weil der Agent einen Thread auf Anforderungen pruefen musste. Dann ein Docs-Tool fuer Ihr internes Wiki.
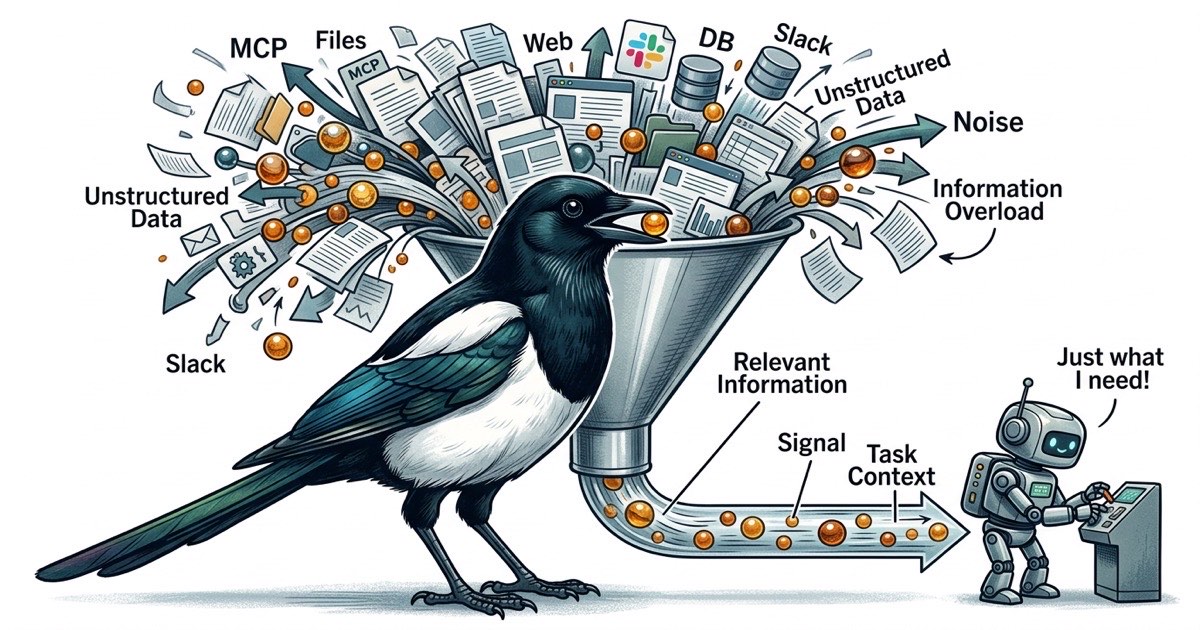
Sechs MCP-Server. Jeder registriert Tool-Schemas im Kontext des Agenten. Jeder erweitert die Flaeche dessen, was der Agent tun koennte, was mehr Tokens fuer Tool-Beschreibungen bedeutet und mehr Gelegenheiten, vom Thema abzuschweifen.
Ihr Agent schreibt immer noch guten Code. Aber er schreibt ihn langsamer, und die Ausgabe ist unberechenbarer geworden. Das bilden Sie sich nicht ein. Das Context Window ist der Flaschenhals, und Sie fuellen es mit Infrastruktur.
Das Akkumulationsproblem
MCP-Server sind leistungsfaehig. Das Model Context Protocol gibt Claude Code Zugang zu externen Systemen, und jede Integration loest ein echtes Problem. Dateizugriff laesst den Agenten Ihre Codebasis lesen. Websuche laesst ihn Dokumentation nachschlagen. GitHub-Integration laesst ihn PR-Status pruefen.
Das Problem beginnt, wenn Sie jeden Bedarf des Agenten durch einen weiteren MCP loesen.
Agent muss das Datenbankschema pruefen? Postgres-MCP hinzufuegen. Agent muss eine Confluence-Seite lesen? Confluence-MCP hinzufuegen. Agent muss eine Slack-Nachricht posten? Slack-MCP hinzufuegen. Jeder einzelne ist berechtigt. Zusammen schaffen sie ein Problem, das schwer zu bemerken ist, bis die Ausgabequalitaet sinkt.
Jeder MCP-Server registriert seine Tools im Gespraechskontext. Ein Dateizugriffs-MCP registriert vielleicht 5-10 Tools. Ein Datenbank-MCP registriert weitere. Ein GitHub-MCP fuegt mehr hinzu. Wenn Sie sechs MCP-Server haben, traegt der Agent Dutzende Tool-Definitionen in seinem Context Window, bevor er eine einzige Zeile Ihres Codes liest.
Diese Tool-Definitionen sind nicht kostenlos. Sie verbrauchen Tokens. Und wichtiger noch: Sie konkurrieren um die Aufmerksamkeit des Agenten. Wenn ein Agent 40 verfuegbare Tools hat, wird jeder Entscheidungspunkt zu einer Verzweigungsfrage: Soll ich das Datei-Tool, das Such-Tool, das Datenbank-Tool oder das GitHub-Tool verwenden? Der Agent verbringt kognitives Budget damit zu entscheiden, wie er an Informationen kommt, statt Informationen zu nutzen, um Ihr Problem zu loesen.
Kontext ist endlich. Aufmerksamkeit ist knapper.
Das Context Window von Claude Code ist gross. Das erzeugt eine gefaehrliche Illusion: dass man endlos Informationen hinzufuegen kann, ohne Konsequenzen.
In der Praxis verschlechtert sich die Agenten-Leistung deutlich, bevor das Context Window voll ist. Das Problem ist nicht die Kapazitaet. Es ist das Signal-Rausch-Verhaeltnis. Ein Agent mit einem 200K-Token-Context-Window arbeitet besser mit 50K Tokens fokussierter, relevanter Information als mit 150K Tokens, bei denen die relevanten Teile ueber Tool-Schemas, API-Antworten und tangentiale Dateiinhalte verstreut sind.
Es ist dasselbe Problem, das Menschen mit zu vielen Browser-Tabs haben. Die Information ist technisch verfuegbar. Sie zu finden dauert laenger als noetig. Man liest Dinge erneut, die man schon gesehen hat, weil der relevante Kontext durch Rauschen aus dem Arbeitsgedaechtnis verdraengt wurde.
Bei Agenten aeussert sich das als:
Kaninchenloecher. Der Agent hat ein Datenbank-Tool, also fragt er das Schema ab. Das Schema ist interessant, also fragt er Daten ab. Die Daten zeigen etwas Unerwartetes, also untersucht er weiter. Zwanzig Minuten spaeter haben Sie eine gruendliche Analyse Ihrer Datenbankinhalte und null Fortschritt beim Feature, das Sie verlangt haben.
Tool-Verwirrung. Mit vielen verfuegbaren Tools waehlt der Agent gelegentlich das falsche. Er nutzt die Websuche, um Dokumentation zu finden, die bereits in einer lokalen Datei steht. Er fragt die Datenbank ab, wenn die Antwort in der Aufgabenbeschreibung steht. Jede falsche Tool-Wahl verschwendet Tokens und erzeugt Rauschen.
Verwaesserter Fokus. Die "Aufmerksamkeit" des Agenten ist eine endliche Ressource innerhalb jeder Generation. Wenn der Kontext Tool-Schemas fuer Dateizugriff, Websuche, Datenbankabfragen, GitHub-Operationen, Slack-Nachrichten und Wiki-Lookups enthaelt, verarbeitet der Agent all das, bevor er Ihre eigentliche Anfrage verarbeitet. Die Aufgabe konkurriert mit dem Werkzeugkasten um kognitive Prioritaet.
Bounded Context: die Alternative zum Tool-Wildwuchs
Die reflexartige Antwort auf "mein Agent braucht Information X" ist, dem Agenten ein Tool zu geben, das X abruft. Aber es gibt einen anderen Ansatz: X in die Aufgabe schreiben.
Das ist das Bounded-Context-Muster. Statt Agenten Zugang zu allem zu geben und zu hoffen, dass sie das Relevante finden, gibt man jedem Agenten eine Aufgabe, die alles enthaelt, was er braucht, um die Arbeit abzuschliessen. Der Agent sucht nicht nach Kontext. Der Kontext wird geliefert.
Der Unterschied ist strukturell. Mit MCP-Wildwuchs sieht der Workflow des Agenten so aus:
- Aufgabe lesen
- Herausfinden, welche Informationen fehlen
- Verschiedene Tools nutzen, um diese Informationen zu sammeln
- Die Informationen zusammenfuehren
- Die eigentliche Arbeit erledigen
Mit Bounded Context sieht es so aus:
- Aufgabe lesen (die allen noetigen Kontext enthaelt)
- Die eigentliche Arbeit erledigen
Die Schritte 2-4 im ersten Workflow sind nicht nur Overhead. Dort gehen Dinge schief. Der Agent sammelt zu viel Information, oder die falsche, oder wird von interessanten aber irrelevanten Daten abgelenkt. Jeder Tool-Aufruf ist ein potenzieller Umweg.
Bounded Context bedeutet nicht, dass Agenten keine Tools nutzen koennen. Dateizugriff bleibt notwendig zum Lesen und Schreiben von Code. Aber es bedeutet, dass der informationelle Kontext (was bauen, warum, welche Dateien, was die Akzeptanzkriterien sind) in der Aufgabe lebt, nicht in einem Tool, das der Agent abfragen muss.
Aufgaben als Kontext-Container strukturieren
Eine Aufgabe, die als Kontext-Container funktioniert, sieht anders aus als ein typisches Jira-Ticket oder GitHub Issue. Sie ist in sich geschlossen. Ein Agent, der sie liest, sollte alles haben, was er braucht, um ohne Abfrage externer Systeme loszulegen.
So sieht das in der Praxis aus:
Title: Add rate limiting to /api/search endpoint
Description:
The /api/search endpoint currently has no rate limiting.
Add a token bucket rate limiter at 100 requests/minute per IP.
Files to modify:
- server/middleware/rate-limit.ts (create new)
- server/routes/search.ts (apply middleware)
- server/config.ts (add RATE_LIMIT_RPM env var)
Acceptance criteria:
- Requests beyond 100/min from same IP return 429
- Rate limit resets after 60 seconds
- Config value overridable via environment variable
- Existing tests still pass
Context:
- We use Express middleware pattern (see server/middleware/auth.ts for example)
- The config module uses dotenv (see server/config.ts lines 1-15)
- No Redis available; use in-memory store. This is a single-instance app.
Dependencies: None. This can run independently.
Beachten Sie, was in der Aufgabe eingebettet ist. Der Agent weiss, welche Dateien er anfassen muss, welchem Muster er folgen soll, welche Einschraenkungen bestehen (kein Redis), und wie genau "fertig" aussieht. Er braucht keinen Datenbank-MCP, um das Schema zu pruefen. Er braucht kein Wiki-Tool, um das Middleware-Muster zu finden. Er muss nicht die Codebasis durchsuchen, um den Config-Ansatz zu verstehen. All das steht in der Aufgabe.
Aufgaben so zu schreiben kostet mehr Aufwand im Vorfeld. Ein typisches Ticket koennte sagen "Rate Limiting fuer Search-Endpoint hinzufuegen" und den Rest dem Agenten ueberlassen. Aber genau dieser Herausfindungsprozess ist es, aus dem MCP-Wildwuchs entsteht: Der Agent braucht Information, also gibt man ihm Tools, und die Tools fressen Kontext.