Вы начали с одного MCP-сервера. Доступ к файлам, чтобы ваш агент Claude Code мог читать и писать проект. Разумно.
Потом добавили веб-поиск. Потом GitHub. Потом инструмент для базы данных, чтобы агент мог напрямую запрашивать вашу схему. Потом Slack, потому что агенту нужно было проверить тред с требованиями. Потом инструмент для документации внутренней wiki.
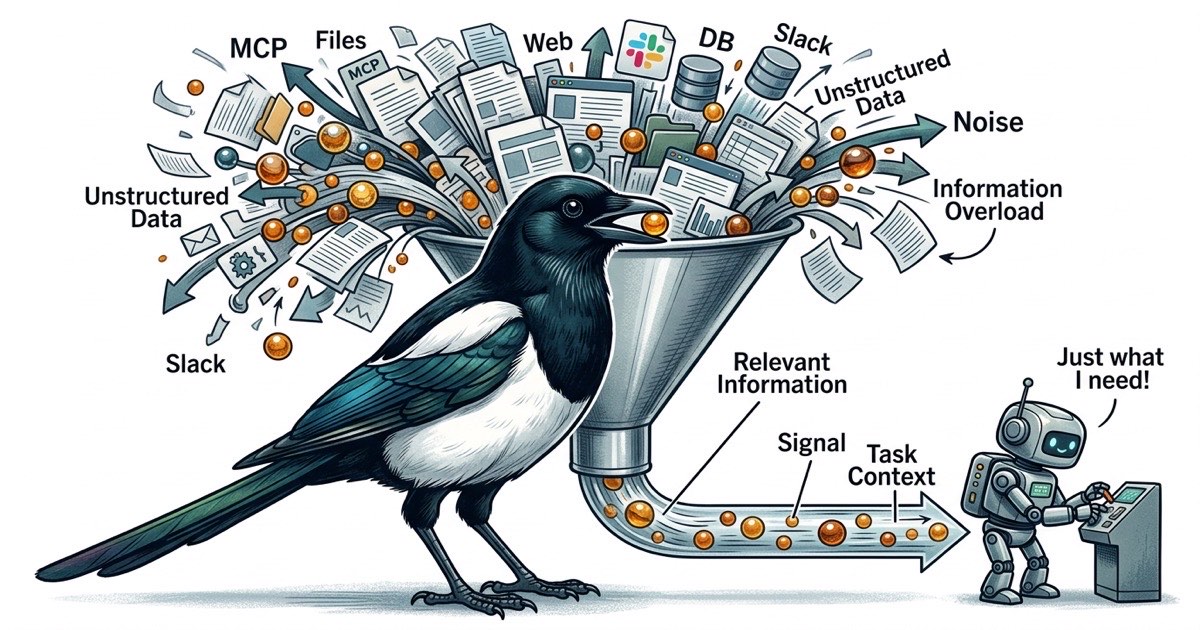
Шесть MCP-серверов. Каждый регистрирует схемы инструментов в контексте агента. Каждый расширяет пространство того, что агент мог бы делать, что означает больше токенов на описания инструментов и больше возможностей для агента отвлечься от задачи.
Ваш агент все еще пишет хороший код. Но пишет медленнее, и результат стал менее предсказуемым. Вам не кажется. Окно контекста стало узким местом, и вы заполняете его инфраструктурой.
Проблема накопления
MCP-серверы мощные. Model Context Protocol дает Claude Code доступ к внешним системам, и каждая интеграция действительно решает проблему. Доступ к файлам позволяет агенту читать кодовую базу. Веб-поиск позволяет искать документацию. Интеграция с GitHub позволяет проверять статус PR.
Проблема начинается, когда вы решаете каждую потребность агента добавлением очередного MCP.
Агенту нужно проверить схему базы данных? Добавить Postgres MCP. Агенту нужно прочитать страницу Confluence? Добавить Confluence MCP. Агенту нужно опубликовать сообщение в Slack? Добавить Slack MCP. Каждый по отдельности обоснован. Вместе они создают проблему, которую трудно заметить, пока качество результатов не упадет.
Каждый MCP-сервер регистрирует свои инструменты в контексте разговора. MCP доступа к файлам может зарегистрировать 5-10 инструментов. MCP базы данных регистрирует еще несколько. GitHub MCP добавляет еще. Когда у вас шесть MCP-серверов, агент несет десятки определений инструментов в своем окне контекста, прежде чем прочитает хоть одну строку вашего кода.
Эти определения инструментов не бесплатны. Они потребляют токены. И что важнее, они конкурируют за внимание агента. Когда у агента 40 доступных инструментов, каждая точка принятия решения становится ветвящимся вопросом: использовать файловый инструмент, поисковый, базу данных или GitHub? Агент тратит когнитивный бюджет на решение как получить информацию, вместо того чтобы использовать информацию для решения вашей задачи.
Контекст конечен. Внимание еще более дефицитно.
Окно контекста Claude Code большое. Это создает опасную иллюзию: что можно продолжать добавлять информацию без последствий.
На практике производительность агента деградирует задолго до заполнения окна контекста. Проблема не в емкости. В соотношении сигнал-шум. Агент с окном контекста в 200K токенов работает лучше с 50K токенов сфокусированной, релевантной информации, чем со 150K токенов, где нужные части разбросаны среди схем инструментов, ответов API и посторонних файлов.
Это та же проблема, с которой сталкиваются люди при слишком многих вкладках браузера. Информация технически доступна. Найти ее занимает больше времени, чем нужно. Вы перечитываете то, что уже видели, потому что релевантный контекст был вытеснен из рабочей памяти шумом.
Для агентов это проявляется как:
Кроличьи норы. У агента есть инструмент базы данных, поэтому он запрашивает схему. Схема интересна, поэтому он запрашивает данные. Данные показывают что-то неожиданное, поэтому он исследует дальше. Двадцать минут спустя у вас есть подробный анализ содержимого базы данных и нулевой прогресс по запрошенной функции.
Путаница инструментов. При множестве доступных инструментов агент иногда выбирает неправильный. Использует веб-поиск для документации, которая уже есть в локальном файле. Запрашивает базу данных, когда ответ в описании задачи. Каждый неверный выбор инструмента тратит токены и вносит шум.
Размытый фокус. «Внимание» агента является конечным ресурсом в каждой генерации. Когда контекст содержит схемы инструментов для доступа к файлам, веб-поиска, запросов к базе данных, операций GitHub, сообщений Slack и просмотра wiki, агент обрабатывает все это прежде, чем обработать ваш фактический запрос. Задача конкурирует с инструментарием за когнитивный приоритет.
Ограниченный контекст: альтернатива разрастанию инструментов
Рефлекторная реакция на «моему агенту нужна информация X» — дать агенту инструмент, который извлекает X. Но есть другой подход: поместить X в задачу.
Это паттерн ограниченного контекста. Вместо того чтобы давать агентам доступ ко всему и надеяться, что они найдут нужное, вы даете каждому агенту задачу, содержащую все необходимое для выполнения работы. Агент не ищет контекст. Контекст доставляется.
Разница структурная. При разрастании MCP рабочий процесс агента выглядит так:
- Прочитать задачу
- Выяснить, какая информация отсутствует
- Использовать различные инструменты для сбора этой информации
- Синтезировать информацию
- Выполнить фактическую работу
При ограниченном контексте:
- Прочитать задачу (которая содержит весь необходимый контекст)
- Выполнить фактическую работу
Шаги 2-4 в первом рабочем процессе — это не просто накладные расходы. Именно там все идет не так. Агент собирает слишком много информации, или неправильную информацию, или отвлекается на интересные, но нерелевантные данные. Каждый вызов инструмента — потенциальный крюк.
Ограниченный контекст не означает, что агенты не могут использовать инструменты. Доступ к файлам по-прежнему необходим для чтения и записи кода. Но это означает, что информационный контекст (что строить, почему, какие файлы, каковы критерии приемки) живет в задаче, а не в инструменте, который агент должен запрашивать.
Структурирование задач как контейнеров контекста
Задача, работающая как контейнер контекста, выглядит иначе, чем типичный тикет Jira или GitHub issue. Она самодостаточна. Агент, прочитавший ее, должен иметь все необходимое для начала работы без обращения к внешним системам за фоновой информацией.
Вот как это выглядит на практике:
Title: Add rate limiting to /api/search endpoint
Description:
The /api/search endpoint currently has no rate limiting.
Add a token bucket rate limiter at 100 requests/minute per IP.
Files to modify:
- server/middleware/rate-limit.ts (create new)
- server/routes/search.ts (apply middleware)
- server/config.ts (add RATE_LIMIT_RPM env var)
Acceptance criteria:
- Requests beyond 100/min from same IP return 429
- Rate limit resets after 60 seconds
- Config value overridable via environment variable
- Existing tests still pass
Context:
- We use Express middleware pattern (see server/middleware/auth.ts for example)
- The config module uses dotenv (see server/config.ts lines 1-15)
- No Redis available; use in-memory store. This is a single-instance app.
Dependencies: None. This can run independently.
Обратите внимание, что встроено в задачу. Агент знает, какие файлы трогать, какому паттерну следовать, какие ограничения существуют (нет Redis), и как именно выглядит «готово». Ему не нужен MCP базы данных для проверки схемы. Не нужен инструмент wiki для поиска паттерна middleware. Не нужно искать по кодовой базе, чтобы понять подход к конфигурации. Все в задаче.
Написание задач таким образом требует больше усилий заранее. Типичный тикет может сказать «Добавить rate limiting к search endpoint» и оставить остальное агенту. Но этот процесс выяснения — именно то, откуда берется разрастание MCP: агенту нужна информация, поэтому вы даете ему инструменты, а инструменты поедают контекст.