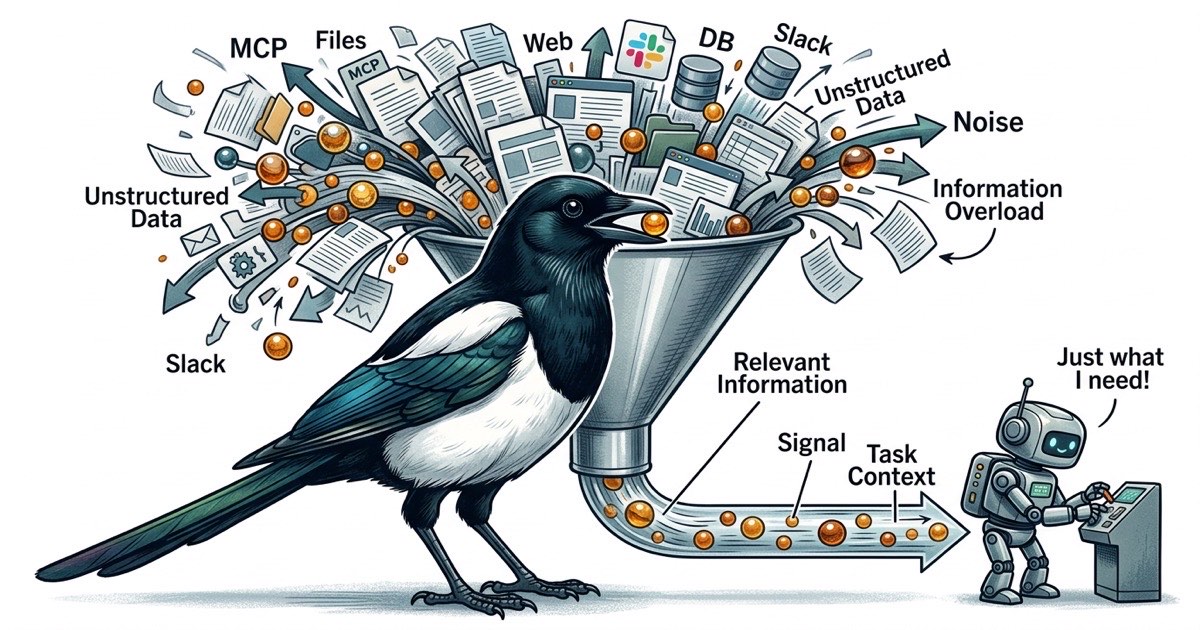
Voce comecou com um servidor MCP. Acesso a arquivos, para que seu agente Claude Code pudesse ler e escrever seu projeto. Razoavel.
Depois adicionou busca web. Depois GitHub. Depois uma ferramenta de banco de dados para que o agente pudesse consultar seu schema diretamente. Depois Slack, porque o agente precisava verificar uma thread para requisitos. Depois uma ferramenta de documentacao para seu wiki interno.
Seis servidores MCP. Cada um registra schemas de ferramentas no contexto do agente. Cada um amplia a superficie do que o agente poderia fazer, o que significa mais tokens gastos em descricoes de ferramentas e mais oportunidades para o agente sair do caminho.
Seu agente ainda escreve bom codigo. Mas escreve mais devagar, e os resultados ficaram menos previsiveis. Voce nao esta imaginando isso. A janela de contexto e o gargalo, e voce esta enchendo ela com encanamento.
O problema da acumulacao
Servidores MCP sao poderosos. O Model Context Protocol da ao Claude Code acesso a sistemas externos, e cada integracao genuinamente resolve um problema. Acesso a arquivos permite ao agente ler sua codebase. Busca web permite consultar documentacao. Integracao com GitHub permite verificar status de PRs.
O problema comeca quando voce resolve cada necessidade do agente adicionando mais um MCP.
Agente precisa verificar o schema do banco? Adiciona um MCP Postgres. Agente precisa ler uma pagina do Confluence? Adiciona um MCP Confluence. Agente precisa postar uma mensagem no Slack? Adiciona um MCP Slack. Cada um e justificado individualmente. Juntos, criam um problema dificil de perceber ate a qualidade dos resultados cair.
Cada servidor MCP registra suas ferramentas no contexto da conversa. Um MCP de acesso a arquivos pode registrar 5-10 ferramentas. Um MCP de banco registra mais algumas. Um MCP de GitHub adiciona outras. Quando voce tem seis servidores MCP, o agente carrega dezenas de definicoes de ferramentas na sua janela de contexto antes de ler uma unica linha do seu codigo.
Essas definicoes de ferramentas nao sao gratis. Consomem tokens. E mais importante, competem pela atencao do agente. Quando um agente tem 40 ferramentas disponiveis, cada ponto de decisao vira uma pergunta ramificada: devo usar a ferramenta de arquivo, a de busca, a de banco de dados ou a do GitHub? O agente gasta orcamento cognitivo decidindo como obter informacao em vez de usar informacao para resolver seu problema.
Contexto e finito. Atencao e mais escassa.
A janela de contexto do Claude Code e grande. Isso cria uma ilusao perigosa: que voce pode continuar adicionando informacao sem consequencias.
Na pratica, o desempenho do agente degrada bem antes da janela de contexto encher. O problema nao e capacidade. E a relacao sinal-ruido. Um agente com janela de contexto de 200K tokens performa melhor com 50K tokens de informacao focada e relevante do que com 150K tokens onde os trechos relevantes estao espalhados entre schemas de ferramentas, respostas de API e conteudos de arquivos tangenciais.
E o mesmo problema que humanos enfrentam com abas demais no navegador. A informacao esta tecnicamente disponivel. Encontra-la leva mais tempo do que deveria. Voce acaba relendo coisas que ja viu porque o contexto relevante foi empurrado para fora da memoria de trabalho pelo ruido.
Para agentes, isso se manifesta como:
Tocas de coelho. O agente tem uma ferramenta de banco de dados, entao consulta o schema. O schema e interessante, entao consulta dados. Os dados revelam algo inesperado, entao investiga mais. Vinte minutos depois, voce tem uma analise completa do conteudo do seu banco de dados e zero progresso na funcionalidade que pediu.
Confusao de ferramentas. Com muitas ferramentas disponiveis, o agente ocasionalmente escolhe a errada. Usa busca web para encontrar documentacao que ja esta num arquivo local. Consulta o banco quando a resposta esta na descricao da tarefa. Cada escolha errada de ferramenta desperidca tokens e introduz ruido.
Foco diluido. A "atencao" do agente e um recurso finito dentro de cada geracao. Quando o contexto contem schemas de ferramentas para acesso a arquivos, busca web, consultas de banco, operacoes GitHub, mensagens Slack e consultas de wiki, o agente processa tudo isso antes de processar sua solicitacao real. A tarefa compete com as ferramentas pela prioridade cognitiva.
Contexto delimitado: a alternativa a proliferacao de ferramentas
A resposta reflexa a "meu agente precisa da informacao X" e dar ao agente uma ferramenta que busca X. Mas existe outra abordagem: colocar X na tarefa.
Esse e o padrao de contexto delimitado. Em vez de dar aos agentes acesso a tudo e torcer para que encontrem o que e relevante, voce da a cada agente uma tarefa que contem tudo que ele precisa para completar o trabalho. O agente nao procura contexto. O contexto e entregue.
A diferenca e estrutural. Com proliferacao de MCPs, o fluxo de trabalho do agente e:
- Ler a tarefa
- Descobrir quais informacoes faltam
- Usar varias ferramentas para coletar essas informacoes
- Sintetizar as informacoes
- Fazer o trabalho real
Com contexto delimitado, e:
- Ler a tarefa (que contem todo o contexto necessario)
- Fazer o trabalho real
Os passos 2-4 do primeiro fluxo nao sao apenas overhead. E la que as coisas dao errado. O agente coleta informacao demais, ou a informacao errada, ou se distrai com dados interessantes mas irrelevantes. Cada invocacao de ferramenta e um desvio potencial.
Contexto delimitado nao significa que agentes nao podem usar ferramentas. Acesso a arquivos continua necessario para ler e escrever codigo. Mas significa que o contexto informacional (o que construir, por que, quais arquivos, quais sao os criterios de aceitacao) vive na tarefa, nao numa ferramenta que o agente precisa consultar.
Estruturando tarefas como conteineres de contexto
Uma tarefa que funciona como conteiner de contexto e diferente de um ticket tipico do Jira ou issue do GitHub. E autocontida. Um agente que a le deveria ter tudo que precisa para comecar a trabalhar sem consultar sistemas externos para informacoes de fundo.
Veja como isso se parece na pratica:
Title: Add rate limiting to /api/search endpoint
Description:
The /api/search endpoint currently has no rate limiting.
Add a token bucket rate limiter at 100 requests/minute per IP.
Files to modify:
- server/middleware/rate-limit.ts (create new)
- server/routes/search.ts (apply middleware)
- server/config.ts (add RATE_LIMIT_RPM env var)
Acceptance criteria:
- Requests beyond 100/min from same IP return 429
- Rate limit resets after 60 seconds
- Config value overridable via environment variable
- Existing tests still pass
Context:
- We use Express middleware pattern (see server/middleware/auth.ts for example)
- The config module uses dotenv (see server/config.ts lines 1-15)
- No Redis available; use in-memory store. This is a single-instance app.
Dependencies: None. This can run independently.
Observe o que esta embutido na tarefa. O agente sabe quais arquivos mexer, qual padrao seguir, quais restricoes existem (sem Redis), e exatamente como "pronto" se parece. Nao precisa de um MCP de banco de dados para verificar o schema. Nao precisa de uma ferramenta de wiki para encontrar o padrao de middleware. Nao precisa buscar na codebase para entender a abordagem de configuracao. Tudo esta na tarefa.
Escrever tarefas assim exige mais esforco inicial. Um ticket tipico poderia dizer "Adicionar rate limiting ao endpoint de busca" e deixar o agente descobrir o resto. Mas esse processo de descoberta e exatamente de onde vem a proliferacao de MCPs: o agente precisa de informacao, entao voce da ferramentas, e as ferramentas consomem contexto.