Hai una feature che richiede tre cose contemporaneamente. Puoi lanciare subagent all'interno di una singola sessione Claude Code e farli lavorare in parallelo. Oppure puoi dividere il lavoro in tre task indipendenti, assegnare ciascuno a un agente separato nel suo pannello tmux, e farli girare senza che sappiano nulla l'uno dell'altro.
Entrambi gli approcci parallelizzano il lavoro. Risolvono problemi diversi. Scegli quello sbagliato e brucerai finestra di contesto in overhead di coordinamento oppure creerai conflitti di merge che richiedono piu tempo per essere risolti del task originale.
Questo e il framework decisionale che uso ogni giorno facendo girare 13 agenti Claude Code sulla stessa codebase. Non e teorico. E il risultato di aver sbagliato abbastanza volte da sapere dove si trova il confine.
Due tipi di parallelismo
Claude Code supporta due modi distinti di eseguire lavoro in modo concorrente.
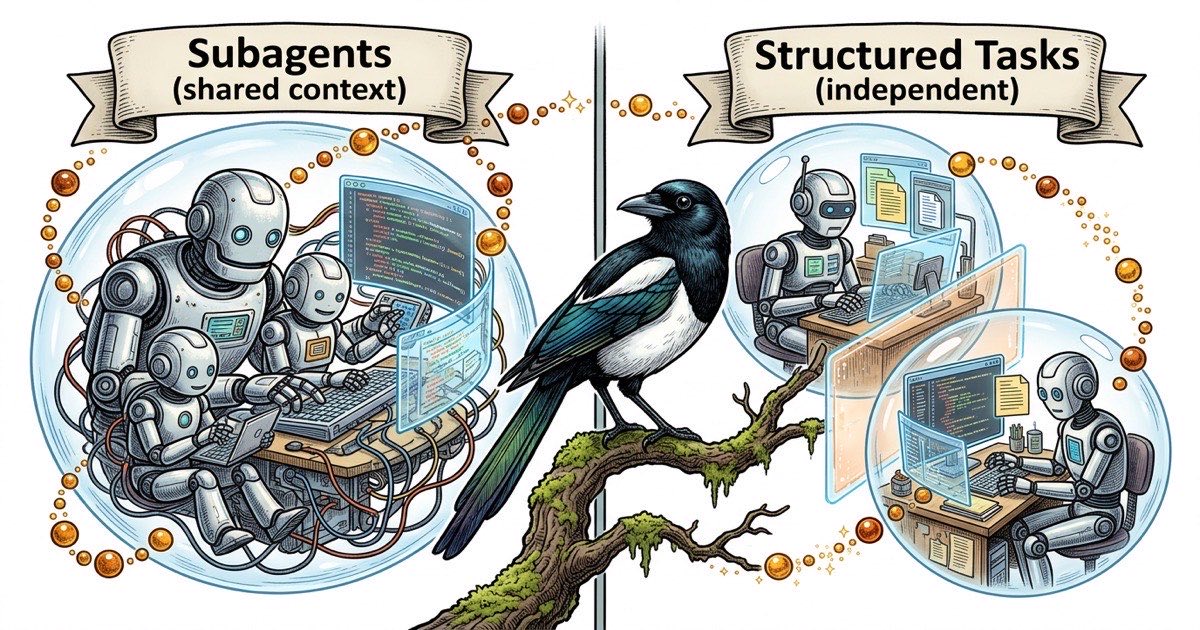
I subagent sono processi figli lanciati all'interno di una singola sessione Claude Code. L'agente padre avvia piu subagent, ciascuno affronta una parte del problema, poi raccoglie i risultati. Condividono la stessa directory di lavoro e il contesto del padre. Pensali come thread in un singolo processo.
Parent agent
├── Subagent A: "Search lib/ for all usages of parseConfig"
├── Subagent B: "Search server/ for all usages of parseConfig"
└── Subagent C: "Search components/ for all usages of parseConfig"
Gli agenti separati girano in sessioni Claude Code indipendenti, tipicamente in pannelli tmux separati. Ciascuno ha la propria finestra di contesto, il proprio file di identita CLAUDE.md e la propria visione della codebase. Non condividono memoria. Comunicano attraverso artefatti: commenti sui task, aggiornamenti di stato, codice committato. Pensali come processi separati senza stato condiviso.
tmux pane 1: eng1 agent → "Build the REST endpoint"
tmux pane 2: eng2 agent → "Build the React component"
tmux pane 3: qa1 agent → "Write integration tests for both"
Il modello mentale conta perche determina come il lavoro fluisce tra le unita. I subagent possono restituire dati al padre a basso costo. Gli agenti separati passano dati attraverso il filesystem, git o un task tracker esterno.
Quando vincono i subagent
Usa i subagent quando il lavoro condivide stato e i risultati devono convergere.
Ricerca parallela. Devi cercare un pattern in cinque directory, leggere tre file di documentazione e sintetizzare i risultati in una raccomandazione. I subagent possono prendere ciascuno un percorso di ricerca, restituire risultati, e il padre puo combinarli senza overhead di serializzazione.
Trasformazioni indipendenti sugli stessi dati. Stai refactorizzando un modulo e devi aggiornare le definizioni dei tipi, i test e la documentazione in un unico cambiamento coerente. Ogni subagent gestisce un file, ma il padre garantisce che le modifiche siano coerenti perche vede tutti e tre i risultati prima di committare.
Esplorazione rapida. Stai debuggando e devi controllare il git log, l'output dei test e la configurazione runtime simultaneamente. I subagent possono raccogliere tutti e tre in parallelo e il padre sintetizza una diagnosi.
Il pattern: distribuire, raccogliere, agire sul risultato combinato. Se il tuo parallelismo finisce con il padre che deve ragionare su tutti gli output insieme, i subagent sono lo strumento giusto.
Dove i subagent falliscono: qualsiasi cosa che richieda piu di qualche minuto per ramo, qualsiasi cosa che modifichi file in percorsi sovrapposti, o qualsiasi cosa che necessiti di verifica indipendente. I subagent condividono una directory di lavoro, quindi due subagent che scrivono nello stesso file corromperanno il lavoro l'uno dell'altro. E poiche condividono il contesto, un subagent di lunga durata consuma la finestra disponibile del padre.
Quando vincono gli agenti separati
Usa agenti separati quando il lavoro puo essere verificato indipendentemente e non ha bisogno di un contesto condiviso per avere senso.
Componenti diversi della stessa feature. "Costruisci l'endpoint API" e "Costruisci il frontend che lo chiama" sono indipendenti fino all'integrazione. L'ingegnere API non ha bisogno del componente React nel suo contesto. L'ingegnere frontend non ha bisogno dello schema del database. Dare a ciascuno il proprio agente con un CLAUDE.md delimitato mantiene il contesto pulito e impedisce alla complessita di un agente di contaminare il lavoro dell'altro.
Criteri di accettazione diversi. Se il task A e completato quando l'endpoint restituisce 200 con la forma JSON corretta, e il task B e completato quando il componente renderizza i dati con gli stati di errore appropriati, questi sono obiettivi di verifica separati. Un agente QA puo validare ciascuno indipendentemente. I subagent non possono essere verificati indipendentemente perche producono un output combinato.
Lavoro che tocca parti diverse della codebase. Il file ownership e il modo piu semplice per prevenire conflitti di merge. L'agente A possiede server/, l'agente B possiede components/. Nessuno entra nel territorio dell'altro. Se provi questo con i subagent, il padre dovrebbe gestire il file locking, il che vanifica lo scopo del parallelismo.
Task con orizzonti temporali diversi. Un task richiede 10 minuti, l'altro 2 ore. Con i subagent, il padre aspetta il figlio piu lento. Con agenti separati, il task breve si completa, viene verificato e shippato mentre il task lungo sta ancora girando.
Il pattern: lanciare, dimenticare, verificare separatamente. Se ogni pezzo di lavoro regge da solo e puo essere controllato da solo, gli agenti separati con task strutturati sono piu puliti.
Il problema del passaggio
Il vero punto decisionale si riduce ai passaggi.
I passaggi dei subagent sono economici. Il figlio restituisce dati al padre nello stesso contesto. Nessuna serializzazione, nessuna scrittura di file, nessuna attesa di aggiornamenti di stato. Il padre lancia tre subagent, restituiscono tre risultati, il padre ha tutto cio di cui ha bisogno.
I passaggi tra agenti separati sono costosi ma durevoli. L'agente A completa il lavoro, committa codice, aggiorna lo stato di un task e commenta cosa ha fatto. L'agente B raccoglie quel segnale (tramite un coordinatore o interrogando il task tracker) e inizia il suo lavoro dipendente. L'overhead e reale: serve un sistema di task, un protocollo di stato e un modo per gli agenti di scoprire cosa hanno fatto gli altri agenti.
La regola pratica: se il lavoro richiede piu di un passaggio tra le unita parallele, usa i subagent. Per un singolo fan-out-and-gather, i subagent sono piu semplici. Se l'output dell'agente A e l'input dell'agente B, che diventa l'input dell'agente C, il costo di coordinamento degli agenti separati e giustificato perche ogni passaggio produce un artefatto verificato e committato che non andra perso se un agente crasha o raggiunge un limite di contesto.
Un esempio concreto. Devi:
- Trovare tutti gli endpoint API che restituiscono dati utente
- Aggiungere rate limiting a ciascuno
- Scrivere test per i nuovi rate limit
- Aggiornare la documentazione API
I passaggi 1 e 2 sono strettamente accoppiati. I risultati della ricerca (passaggio 1) alimentano direttamente la modifica (passaggio 2). Un subagent gestisce la ricerca; il padre applica le modifiche. Questo e un pattern da subagent.
I passaggi 3 e 4 sono indipendenti tra loro ma dipendono dal passaggio 2. I test hanno bisogno del codice reale dell'endpoint. La documentazione ha bisogno della forma finale dell'API. Questi sono task separati per agenti separati, ciascuno con i propri criteri di accettazione, ciascuno verificabile autonomamente.