Hai iniziato con un solo server MCP. Accesso ai file, cosi il tuo agente Claude Code potesse leggere e scrivere il tuo progetto. Ragionevole.
Poi hai aggiunto la ricerca web. Poi GitHub. Poi uno strumento per il database cosi l'agente potesse interrogare il tuo schema direttamente. Poi Slack, perche l'agente doveva controllare un thread per i requisiti. Poi uno strumento per la documentazione del tuo wiki interno.
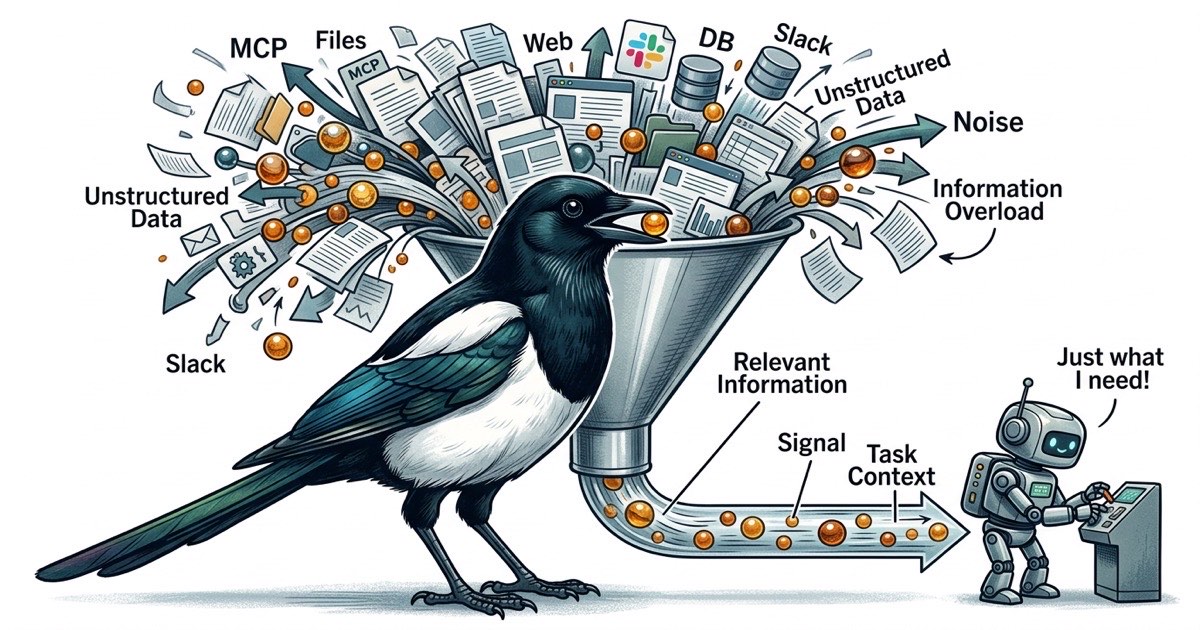
Sei server MCP. Ognuno registra schema di strumenti nel contesto dell'agente. Ognuno amplia la superficie di cio che l'agente potrebbe fare, il che significa piu token spesi in descrizioni di strumenti e piu opportunita per l'agente di divagare.
Il tuo agente scrive ancora buon codice. Ma lo scrive piu lentamente, e i risultati sono diventati meno prevedibili. Non te lo stai immaginando. La finestra di contesto e il collo di bottiglia, e la stai riempiendo con infrastruttura.
Il problema dell'accumulo
I server MCP sono potenti. Il Model Context Protocol da a Claude Code accesso a sistemi esterni, e ogni integrazione risolve genuinamente un problema. L'accesso ai file permette all'agente di leggere la tua codebase. La ricerca web gli permette di consultare documentazione. L'integrazione con GitHub gli permette di controllare lo stato delle PR.
Il problema inizia quando risolvi ogni esigenza dell'agente aggiungendo un altro MCP.
L'agente deve controllare lo schema del database? Aggiungi un MCP Postgres. L'agente deve leggere una pagina Confluence? Aggiungi un MCP Confluence. L'agente deve postare un messaggio su Slack? Aggiungi un MCP Slack. Ognuno e giustificato individualmente. Collettivamente, creano un problema difficile da notare finche la qualita dell'output non cala.
Ogni server MCP registra i suoi strumenti nel contesto della conversazione. Un MCP di accesso ai file potrebbe registrare 5-10 strumenti. Un MCP database ne registra altri. Un MCP GitHub ne aggiunge ancora. Quando hai sei server MCP, l'agente porta dozzine di definizioni di strumenti nella sua finestra di contesto prima di leggere una singola riga del tuo codice.
Quelle definizioni di strumenti non sono gratuite. Consumano token. E soprattutto, competono per l'attenzione dell'agente. Quando un agente ha 40 strumenti disponibili, ogni punto decisionale diventa una domanda ramificata: devo usare lo strumento file, quello di ricerca, quello database o quello GitHub? L'agente spende budget cognitivo per decidere come ottenere informazioni invece di usare informazioni per risolvere il tuo problema.
Il contesto e finito. L'attenzione lo e ancora di piu.
La finestra di contesto di Claude Code e grande. Questo crea un'illusione pericolosa: che puoi continuare ad aggiungere informazioni senza conseguenze.
In pratica, le performance dell'agente si degradano ben prima che la finestra di contesto si riempia. Il problema non e la capacita. E il rapporto segnale-rumore. Un agente con una finestra di contesto di 200K token performa meglio con 50K token di informazioni focalizzate e rilevanti che con 150K token dove i pezzi rilevanti sono dispersi tra schema di strumenti, risposte API e contenuti di file tangenziali.
E lo stesso problema che gli umani affrontano con troppi tab del browser. L'informazione e tecnicamente disponibile. Trovarla richiede piu tempo del dovuto. Finisci per rileggere cose che hai gia visto perche il contesto rilevante e stato spinto fuori dalla memoria di lavoro dal rumore.
Per gli agenti, questo si manifesta come:
Tane di coniglio. L'agente ha uno strumento database, quindi interroga lo schema. Lo schema e interessante, quindi interroga dei dati. I dati rivelano qualcosa di inaspettato, quindi indaga ulteriormente. Venti minuti dopo, hai un'analisi approfondita dei contenuti del tuo database e zero progressi sulla funzionalita che avevi chiesto.
Confusione di strumenti. Con molti strumenti disponibili, l'agente occasionalmente sceglie quello sbagliato. Usa la ricerca web per trovare documentazione che e gia in un file locale. Interroga il database quando la risposta e nella descrizione del task. Ogni scelta sbagliata di strumento spreca token e introduce rumore.
Focus diluito. L'attenzione dell'agente e una risorsa finita all'interno di ogni generazione. Quando il contesto contiene schema di strumenti per accesso ai file, ricerca web, query database, operazioni GitHub, messaggi Slack e consultazioni wiki, l'agente elabora tutto questo prima di elaborare la tua richiesta effettiva. Il task compete con gli strumenti per la priorita cognitiva.
Contesto delimitato: l'alternativa alla proliferazione di strumenti
La risposta riflessa a "il mio agente ha bisogno dell'informazione X" e dare all'agente uno strumento che recupera X. Ma c'e un altro approccio: mettere X nel task.
Questo e il pattern del contesto delimitato. Invece di dare agli agenti accesso a tutto e sperare che trovino cio che e rilevante, dai a ogni agente un task che contiene tutto cio di cui ha bisogno per completare il lavoro. L'agente non cerca contesto. Il contesto viene consegnato.
La differenza e strutturale. Con la proliferazione di MCP, il flusso di lavoro dell'agente appare cosi:
- Leggere il task
- Capire quali informazioni mancano
- Usare vari strumenti per raccogliere quelle informazioni
- Sintetizzare le informazioni
- Fare il lavoro vero e proprio
Con il contesto delimitato, appare cosi:
- Leggere il task (che contiene tutto il contesto necessario)
- Fare il lavoro vero e proprio
I passaggi 2-4 del primo flusso di lavoro non sono solo overhead. E li che le cose vanno storte. L'agente raccoglie troppe informazioni, o le informazioni sbagliate, o si distrae con dati interessanti ma irrilevanti. Ogni invocazione di strumento e una potenziale deviazione.
Contesto delimitato non significa che gli agenti non possano usare strumenti. L'accesso ai file resta necessario per leggere e scrivere codice. Ma significa che il contesto informativo (cosa costruire, perche, quali file, quali sono i criteri di accettazione) vive nel task, non in uno strumento che l'agente deve interrogare.
Strutturare i task come contenitori di contesto
Un task che funziona come contenitore di contesto appare diverso da un tipico ticket Jira o issue GitHub. E autocontenuto. Un agente che lo legge dovrebbe avere tutto cio di cui ha bisogno per iniziare a lavorare senza interrogare sistemi esterni per informazioni di contesto.
Ecco come appare in pratica:
Title: Add rate limiting to /api/search endpoint
Description:
The /api/search endpoint currently has no rate limiting.
Add a token bucket rate limiter at 100 requests/minute per IP.
Files to modify:
- server/middleware/rate-limit.ts (create new)
- server/routes/search.ts (apply middleware)
- server/config.ts (add RATE_LIMIT_RPM env var)
Acceptance criteria:
- Requests beyond 100/min from same IP return 429
- Rate limit resets after 60 seconds
- Config value overridable via environment variable
- Existing tests still pass
Context:
- We use Express middleware pattern (see server/middleware/auth.ts for example)
- The config module uses dotenv (see server/config.ts lines 1-15)
- No Redis available; use in-memory store. This is a single-instance app.
Dependencies: None. This can run independently.
Nota cosa e incorporato nel task. L'agente sa quali file toccare, quale pattern seguire, quali vincoli esistono (niente Redis), e esattamente come appare "fatto." Non ha bisogno di un MCP database per controllare lo schema. Non ha bisogno di uno strumento wiki per trovare il pattern del middleware. Non ha bisogno di cercare nella codebase per capire l'approccio alla configurazione. Tutto e nel task.
Scrivere task in questo modo richiede piu sforzo iniziale. Un ticket tipico potrebbe dire "Aggiungi rate limiting all'endpoint di ricerca" e lasciare all'agente il compito di capire il resto. Ma quel processo di comprensione e esattamente da dove viene la proliferazione di MCP: l'agente ha bisogno di informazioni, quindi gli dai strumenti, e gli strumenti consumano contesto.