Vous pouvez faire tourner 10 agents IA de programmation en parallèle aujourd'hui. Donnez un issue à chacun, pointez-les vers une base beads partagée et laissez-les travailler. Les agents créent des sous-tâches, signalent les bugs qu'ils découvrent, mettent à jour les statuts et ferment les issues quand ils ont terminé. C'est véritablement productif.
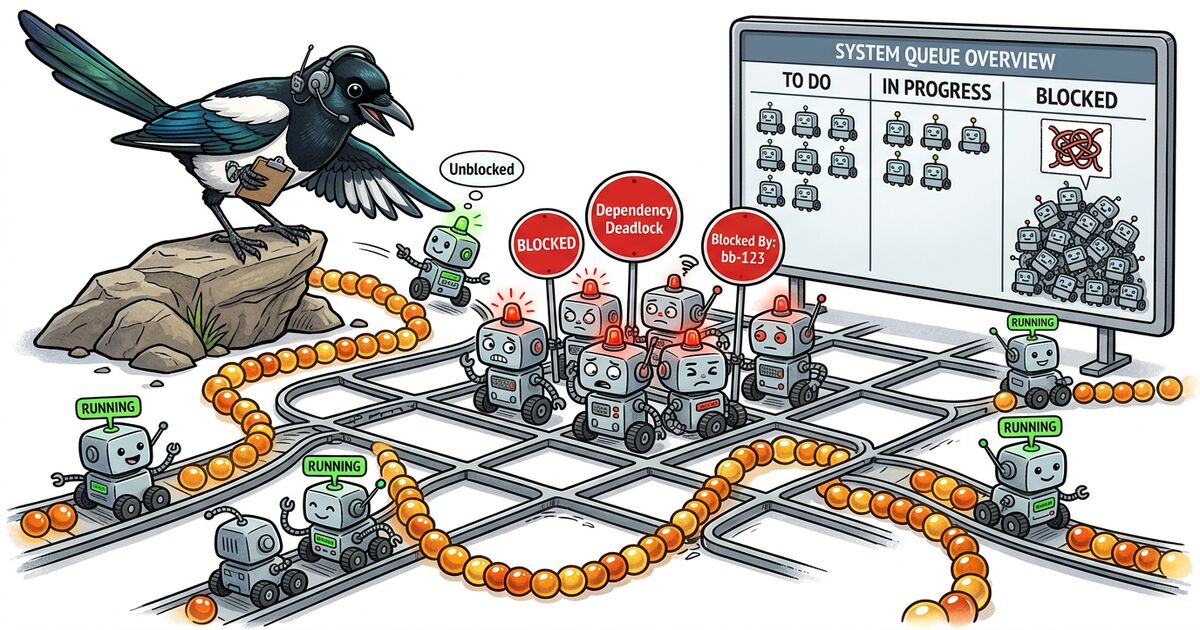
Jusqu'à ce que quelque chose bloque.
Quand un humain est bloqué, il le dit. Il poste sur Slack, le signale en standup, va voir quelqu'un. Les agents ne font rien de tout ça. Un agent rencontre une dépendance qu'il ne peut pas résoudre, et il cale en silence ou contourne le problème d'une manière qui en crée de nouveaux. Trois agents peuvent être coincés sur la même tâche amont non résolue sans que vous le sachiez, jusqu'à ce que vous vous demandiez pourquoi rien n'a été livré depuis quatre heures.
C'est le problème du triage pour le développement agentique. Pas « comment améliorer nos standups » mais « comment voir ce qui est coincé à travers une flotte de travailleurs autonomes qui ne se plaignent pas. » Voici ce que nous avons appris en construisant Beadbox, un dashboard en temps réel pour beads qui montre exactement ce que font vos agents, ce qui les bloque et ce qui vient de se libérer.
Accédez directement à ce qui vous intéresse :
- Comment les agents créent des chaînes de blocage -- les patterns propres au travail agentique
- Détection automatique des dépendances -- capturer les blocages dès leur formation
- Un workflow de triage CLI-first -- scriptable, exécutable par les agents
- Visibilité en temps réel -- voir les blocages au moment où ils surviennent
- Évaluer les outils de triage -- quoi chercher
- La boucle du superviseur -- comment nous gérons 10+ agents au quotidien
Comment les agents créent des chaînes de blocage
Les agents génèrent des problèmes de dépendance différemment des équipes humaines. Comprendre les modes de défaillance est important parce que les réponses de triage diffèrent.
Les agents ne modélisent pas les dépendances en amont. Un architecte humain décompose une fonctionnalité en tâches et réfléchit à l'ordonnancement. Un agent de programmation reçoit une tâche, commence à travailler et découvre en cours d'implémentation qu'il a besoin de quelque chose qui n'existe pas encore. Il peut créer un nouvel issue pour cette dépendance. Il peut essayer de la construire en ligne et créer un désordre. Il peut simplement s'arrêter. Aucune de ces issues n'est visible sans surveillance de la base de données.
Les agents travaillent plus vite que les graphes de dépendances ne se mettent à jour. L'Agent-3 ferme une tâche que l'Agent-7 attendait, mais l'Agent-7 ne le sait pas parce qu'il a vérifié les blocages il y a 10 minutes. Pendant ce temps, l'Agent-7 est toujours inactif ou travaille sur quelque chose de moindre priorité. Le déblocage a eu lieu, mais l'information ne s'est pas propagée.
Les dépendances circulaires émergent de la décomposition parallèle. Quand plusieurs agents décomposent le travail simultanément, ils peuvent créer des cycles qu'aucun agent isolé ne voit. L'Agent-1 crée la Tâche A qui dépend de la Tâche B. L'Agent-2 crée la Tâche B qui dépend de la Tâche C. L'Agent-3 crée la Tâche C qui dépend de la Tâche A. Chaque dépendance avait du sens localement. Le cycle n'est visible que d'en haut.
La contention de ressources est invisible. Deux agents ont besoin de modifier le même fichier, ou d'utiliser l'environnement de staging, ou la même bibliothèque partagée dans un état stable. Aucune dépendance n'est déclarée parce qu'aucun agent ne sait que l'autre existe. Ils ralentissent tous les deux sans que ni l'un ni l'autre ne signale pourquoi.
Le fil conducteur : les agents produisent des situations de blocage plus vite qu'ils ne les signalent. Le superviseur (vous) a besoin d'outils qui remontent les blocages automatiquement, pas d'outils qui attendent que quelqu'un lève un drapeau.
Détection automatique des dépendances
La solution est des données de dépendance explicites, interrogeables, créées au moment de la tâche et vérifiées en continu. Voici à quoi ça ressemble avec beads, le tracker d'issues Git-native sur lequel nous faisons tourner notre flotte d'agents.
Les agents enregistrent les dépendances à la création des tâches :
# L'agent crée une tâche et découvre qu'il a besoin d'une API inexistante
API_TASK=$(bd create \
--title "Implement /api/v2/orders endpoint" \
--type task --priority 2 --json | jq -r '.id')
# L'agent crée sa propre tâche et déclare la dépendance
UI_TASK=$(bd create \
--title "Build order history page" \
--type task --priority 2 --json | jq -r '.id')
bd dep add "$UI_TASK" "$API_TASK"
Ce bd dep add est un seul appel CLI. N'importe quel agent IA de programmation (Claude Code, Cursor, Copilot Workspace) peut l'exécuter. Pas de bibliothèque client, pas de danse d'authentification. La dépendance est désormais une donnée structurée, interrogeable par tout autre agent ou script.
La détection de cycles s'exécute automatiquement :
# beads vérifie le graphe complet de dépendances pour les cycles
bd dep cycles
# Sortie quand des cycles existent :
# CYCLE DETECTED: beads-a1b -> beads-c3d -> beads-e5f -> beads-a1b
Sur un graphe de 5 000 dépendances, ça prend environ 70 ms. Exécutez-le comme hook post-commit ou en cron toutes les 5 minutes. Quand trois agents créent indépendamment un cycle de dépendances, vous le détectez en minutes au lieu de le découvrir des heures plus tard quand les trois sont bloqués.
Afficher toutes les tâches bloquées en une commande :
bd blocked --json | jq -r '.[] |
"BLOCKED: \(.id) \(.title)\n waiting on: \(.blocked_by | join(", "))\n assignee: \(.owner // "unassigned")\n"'
Sortie :
BLOCKED: beads-x7q Build order history page
waiting on: beads-m2k Implement /api/v2/orders endpoint
assignee: agent-3
BLOCKED: beads-r4p Deploy staging environment
waiting on: beads-j9w Fix Docker build, beads-n1c Update TLS certificates
assignee: agent-7
Maintenant vous savez que l'Agent-3 et l'Agent-7 sont coincés, sur quoi ils sont coincés et ce qu'il faut faire pour les débloquer. La requête entière a pris 30 ms sur une base de 10 000 issues.
Détecter les PRs bloquées via les conventions de nommage de branches :
#!/bin/bash
# blocked-prs.sh: trouver les PRs dont les dépendances n'ont pas été mergées
for pr in $(gh pr list --json number,headRefName --jq '.[].headRefName'); do
ISSUE_ID=$(echo "$pr" | grep -oE 'beads-[a-z0-9]+')
[ -z "$ISSUE_ID" ] && continue
BLOCKERS=$(bd show "$ISSUE_ID" --json | jq -r '.blocked_by[]' 2>/dev/null)
for blocker in $BLOCKERS; do
BLOCKER_STATUS=$(bd show "$blocker" --json | jq -r '.status')
if [ "$BLOCKER_STATUS" != "closed" ]; then
echo "PR ($pr) blocked: $ISSUE_ID waiting on $blocker ($BLOCKER_STATUS)"
fi
done
done
Vingt lignes de shell. Tourne localement, lit des données locales, vous dit quelles PRs de vos agents ne peuvent pas encore être mergées et pourquoi.
Un workflow de triage CLI-first
Le triage dans un workflow agentique n'est pas une réunion. C'est un script qui tourne en boucle. Le superviseur (humain ou agent) regarde ce qui est bloqué et prend une décision pour chaque élément.
Voici le script de triage que nous utilisons réellement :
#!/bin/bash
# triage.sh: triage des blocages de la flotte agentique
echo "========================================="
echo "TRIAGE REPORT: $(date +%Y-%m-%d %H:%M)"
echo "========================================="
# 1. Qu'est-ce qui est bloqué ?
echo -e "\n--- BLOCKED TASKS ---"
bd blocked --json | jq -r '.[] |
"[\(.priority)] \(.id) \(.title)
blocked by: \(.blocked_by | join(", "))
assignee: \(.owner // "unassigned")\n"'
# 2. Qu'est-ce qui est disponible pour les agents ?
echo -e "\n--- READY (unblocked, open) ---"
bd ready --json | jq -r '.[] |
"[\(.priority)] \(.id) \(.title) (\(.owner // "unassigned"))"'
# 3. Quels agents sont devenus silencieux ?
echo -e "\n--- STALE IN-PROGRESS (no update in 2h) ---"
CUTOFF=$(date -v-2H +%Y-%m-%dT%H:%M:%S 2>/dev/null || date -d '2 hours ago' --iso-8601=seconds)
bd list --status=in_progress --json | jq -r --arg cutoff "$CUTOFF" '.[] |
select(.updated_at < $cutoff) |
"STALE: \(.id) \(.title) (last update: \(.updated_at), assignee: \(.owner // "unknown"))"'
# 4. Santé des dépendances
echo -e "\n--- DEPENDENCY CYCLES ---"
bd dep cycles 2>&1 || echo "No cycles detected."
echo -e "\n--- FLEET STATS ---"
bd stats
Pour les équipes humaines, « stale » signifie 48 heures sans mise à jour. Pour les agents, 2 heures de silence sur une tâche en cours est un signal d'alerte. Soit l'agent est coincé et ne le signale pas, soit il a planté. Dans les deux cas, il faut regarder.
L'arbre de décision pour chaque élément bloqué :
- Un autre agent peut-il le débloquer ? Repriorisez la tâche bloquante, assignez un agent disponible.
- La dépendance est-elle fausse ? Les agents déclarent parfois des dépendances trop conservatrices pendant la planification. Si le blocage n'est pas réel, supprimez-le :
bd dep remove beads-x7q beads-m2k(supprime la dépendance de x7q sur m2k, débloquant x7q instantanément). - Le travail peut-il être divisé ? Faites traiter à l'agent bloqué les parties qui ne nécessitent pas la dépendance. Créez une tâche de suivi pour le reste.
- Est-ce un blocage externe ? Quelque chose que seul un humain peut résoudre (clé API, décision de design, accès). Étiquetez-le, notez la résolution attendue et réassignez l'agent à d'autre travail disponible.
L'option 2 arrive constamment avec les agents. Ils modélisent les dépendances selon leur compréhension du codebase au moment de la planification. Une fois l'implémentation commencée, la forme réelle du travail révèle que la moitié de ces dépendances étaient inutiles.
Visibilité en temps réel sur le travail des agents
Exécuter un script de triage toutes les 30 minutes laisse des trous. Quand les agents travaillent vite, beaucoup de choses se passent entre les vérifications. La question devient : pouvez-vous voir les blocages se former en temps réel ?
Comment Beadbox le fait :
La base beads vit dans un répertoire .beads/ sur votre système de fichiers. Chaque bd update, bd create ou bd close qu'un agent exécute écrit dans ce répertoire. Beadbox le surveille avec fs.watch() et pousse les changements vers l'interface via WebSocket en quelques millisecondes.
L'effet pratique : l'Agent-5 exécute bd update beads-x7q --status=closed dans un terminal. Le dashboard Beadbox affiche immédiatement cette tâche comme fermée, et toute tâche qui en dépendait s'illumine comme nouvellement disponible. Vous voyez la cascade sans exécuter aucune commande.
Cela compte parce que le travail agentique produit des rafales. Un agent peut fermer trois tâches en 90 secondes, chacune débloquant un travail en aval différent. Un dashboard basé sur du polling avec un intervalle de 30 secondes afficherait un état intermédiaire confus. La propagation en moins d'une seconde montre l'image complète telle qu'elle se forme.
Si vous n'utilisez pas Beadbox, la surveillance du système de fichiers fonctionne quand même :
# Surveiller la base beads pour les changements, alerter sur les nouveaux blocages
# Note : fswatch se déclenche à chaque écriture. En production, vous ajouteriez
# un debounce (ex. sleep 2 après chaque déclenchement) pour éviter le bruit.
fswatch -o .beads/ | while read; do
BLOCKED_COUNT=$(bd blocked --json | jq length)
if [ "$BLOCKED_COUNT" -gt 0 ]; then
echo "$(date): $BLOCKED_COUNT tasks currently blocked"
# Envoyer vers ntfy, webhook Slack, ou tout système de notification
fi
done
Boucler avec la CI :
# Dans votre étape post-build CI : fermer automatiquement l'issue quand le build passe
if [ "$BUILD_STATUS" = "success" ]; then
ISSUE_ID=$(echo "$BRANCH_NAME" | grep -oE 'beads-[a-z0-9]+')
if [ -n "$ISSUE_ID" ]; then
bd update "$ISSUE_ID" --status=closed
bd comments add "$ISSUE_ID" --author ci \
"Build passed. Commit: $COMMIT_SHA. Closing automatically."
fi
fi
Quand la CI ferme cet issue, tout ce qu'il bloquait se retrouve débloqué. Si un agent surveille bd ready pour du nouveau travail, il récupère la tâche débloquée automatiquement. Aucun humain dans la boucle pour les déblocages routiniers.
C'est la différence entre les outils qui suivent le statut et ceux qui le propagent. La plupart des logiciels de gestion de projet font le premier : vous mettez à jour une carte, la carte change de couleur. La propagation signifie que les effets en aval (déblocage des dépendants, remontée du travail disponible, mise à jour des rollups de progression) se produisent sans que personne ne clique quoi que ce soit.
Évaluer les outils de triage pour les workflows agentiques
Si vous cherchez des outils pour gérer une flotte d'agents, les exigences diffèrent de ce dont une équipe humaine a besoin.
Indispensable : un CLI que les agents peuvent appeler. Si votre tracker n'a qu'une interface web, les agents ne peuvent pas l'utiliser. Ils ont besoin d'exécuter des commandes shell. bd create, bd update, bd blocked sont des one-liners que tout agent de programmation sait déjà exécuter. Les API REST fonctionnent aussi, mais elles nécessitent des tokens d'auth, des clients HTTP et de la gestion d'erreurs. Les pipes Unix sont plus simples.
Indispensable : un graphe de dépendances interrogeable. « Bloqué » comme label de statut est inutile pour l'automatisation. Il faut « A dépend de B » comme donnée structurée pour que les scripts puissent traverser le graphe, détecter les cycles et calculer ce qui est prêt.
Indispensable : des lectures locales en moins d'une seconde. Quand les agents interrogent le travail disponible, le temps de réponse compte. Un aller-retour API de 2 secondes par requête, multiplié par 10 agents qui interrogent chaque minute, crée un overhead mesurable. beads retourne les résultats de bd ready en 30 ms sur une base de 10 000 issues parce que tout est local.
Souhaitable : propagation des changements en temps réel. Si les agents créent et résolvent 50 issues par heure, il faut voir l'état tel qu'il change, pas à intervalle de rafraîchissement.
Signal d'alerte : « détection de blocages par IA ». Les outils qui prétendent détecter les blocages en analysant les descriptions d'issues produisent des faux positifs et manquent les vrais blocages jamais documentés. Les déclarations explicites bd dep add battent l'inférence.
Signal d'alerte : outils qui nécessitent un navigateur pour trier. Débloquer une tâche via une interface web prend 5 à 15 secondes de clics. Via le CLI, bd dep remove prend 18 ms. Sur 50 tâches bloquées, c'est 1 minute contre 12 minutes. Quand vous supervisez des agents rapides, la vitesse de triage est votre goulot d'étranglement.
Comment les outils courants gèrent le blocage
| Capacité | Jira | Linear | GitHub Issues | beads + Beadbox |
|---|---|---|---|---|
| Suivi des dépendances | Plugin (Advanced Roadmaps) | Relations (partiel) | Références tasklist | Natif bd dep add |
| Statut bloqué auto | Manuel | Manuel | Manuel | Automatique via deps |
| Détection de cycles | Non | Non | Non | Intégrée (bd dep cycles) |
| CLI pour agents | Jira CLI (tiers) | Linear CLI (limité) | gh (pas de deps) |
Complet (bd blocked, bd ready) |
| Propagation temps réel | Webhook (côté serveur) | Webhook (côté serveur) | Webhook (côté serveur) | fs.watch (sub-seconde, local) |
| Fonctionne hors ligne / local | Non | Non | Non | Oui (mode embarqué) |
| Scriptable par agents | API + tokens auth | API + tokens auth | CLI gh |
CLI bd (pipes Unix) |
La boucle du superviseur
Voici le workflow que nous exécutons quotidiennement, en gérant 10+ agents IA sur un seul projet :
-
Les agents déclarent les dépendances à la création des tâches. Chaque
bd createqui a un prérequis reçoit unbd dep addimmédiatement. C'est un seul appel CLI supplémentaire par tâche. -
Un agent superviseur exécute
bd blockedtoutes les 30 minutes. Si quelque chose est nouvellement bloqué, il résout le blocage lui-même (repriorisation, réassignation) ou le signale à l'humain. -
Beadbox tourne sur l'écran de l'humain. Le dashboard affiche le graphe complet de dépendances avec les tâches bloquées mises en évidence en temps réel. La plupart du temps, l'automatisation gère les déblocages routiniers. Quand elle ne peut pas (dépendance externe, décision architecturale, accès à accorder), l'humain voit le problème immédiatement et intervient.
-
Les tâches stagnantes sont signalées agressivement. Un agent qui n'a pas mis à jour sa tâche en cours depuis 2 heures est soit coincé, soit planté. Le superviseur vérifie et soit relance l'agent, réassigne le travail, soit enquête.
-
Les fausses dépendances sont élaguées en continu. Les agents sur-déclarent les dépendances pendant la planification. Au fur et à mesure que l'implémentation révèle la forme réelle du travail, le superviseur (ou les agents eux-mêmes) supprime les dépendances qui se sont avérées inutiles. Un graphe propre est un graphe utile.
Le principe sous-jacent : les agents sont rapides mais pas conscients d'eux-mêmes. Ils ne savent pas ce que font les autres agents, ne remarquent pas quand les blocages se résolvent et ne se plaignent pas quand ils sont coincés. Le rôle du superviseur est d'être le système nerveux qui connecte tout cela. Des données de dépendance structurées, interrogées automatiquement et rendues visuellement, voilà ce qui rend ça possible.
Beadbox est gratuit pendant la bêta. Il montre ce que font vos agents, ce qui est bloqué et ce qui vient de se libérer, en temps réel.
brew tap beadbox/cask && brew install --cask beadbox
Si vous utilisez déjà beads, Beadbox lit votre répertoire .beads/ existant sans aucune étape d'import. Essayez-le.