Il y a un fosse grandissant entre les developpeurs qui obtiennent des resultats fiables de Claude Code et ceux qui passent la moitie de leur journee a defaire ce que l'agent vient de construire. La difference n'est ni le talent, ni l'experience, ni un quelconque secret de prompt engineering. C'est une question de methodologie. Les developpeurs qui livrent du logiciel de production avec des agents IA ont converge vers un schema, qu'ils le nomment ou non : definir ce que l'on veut avant que l'agent commence a ecrire du code.
Cet article donne un nom a ce schema. Le developpement spec-first est une methodologie pour l'ingenierie logicielle assistee par IA. Pas une vague "bonne pratique." Un cycle de vie structure et reproductible avec des phases definies, des checkpoints clairs et des artefacts concrets a chaque etape. Si vous cherchez un moyen de rendre la sortie de Claude Code assez previsible pour y engager votre calendrier de releases, voici le framework.
Le plafond du Vibe Coding
"Vibe coding" est entre dans le vocabulaire debut 2025. La proposition : decrivez ce que vous voulez en langage naturel, laissez l'IA l'ecrire, iterez jusqu'a ce que ca semble correct. Pour les prototypes, les projets du weekend et les scripts ponctuels, le vibe coding fonctionne. On obtient quelque chose de fonctionnel rapidement, et si ca casse plus tard, les enjeux sont faibles.
Le logiciel de production opere sous des contraintes differentes. Le code doit s'integrer a une codebase existante, satisfaire des exigences specifiques et survivre au contact avec d'autres personnes qui le maintiendront. Quand le vibe coding rencontre ces contraintes, les modes d'echec sont previsibles.
Le premier echec est la derive. Vous decrivez une fonctionnalite vaguement, l'agent implemente son interpretation, vous ajustez, l'agent reimplemente son interpretation ajustee. Trois iterations plus tard, vous avez du code fonctionnel qui ne satisfait aucune de vos exigences originales parce que chaque iteration a deplace la cible. Vous convergez vers ce que l'agent pense que vous voulez, pas vers ce dont vous avez reellement besoin.
Le deuxieme echec, ce sont les decisions invisibles. Chaque lacune dans votre description est une decision que l'agent prend silencieusement. Schema de base de donnees, strategie de gestion d'erreurs, forme de l'API, regles de validation, choix de librairies. Vous decouvrez ces decisions lors de la revue de code, ou pire, en production. L'agent n'a pas pris de mauvaises decisions. Il a pris des decisions non commandees, et vous n'aviez aucun mecanisme pour les detecter avant qu'elles ne soient integrees dans l'implementation.
Le troisieme echec est la paralysie de revue. Un diff de 600 lignes ou l'agent a choisi l'architecture, le modele de donnees, les codes d'erreur et la gestion des cas limites n'est pas revisable au sens traditionnel. Vous ne revisez pas du code contre une spec. Vous reconstituez la spec a partir du code, puis decidez si vous etes d'accord. Cela prend plus de temps que l'ecriture de la spec n'en aurait pris.
Le vibe coding atteint un plafond parce qu'il confond deux activites distinctes : decider quoi construire et le construire. Le developpement spec-first les separe.
Spec-First comme methodologie
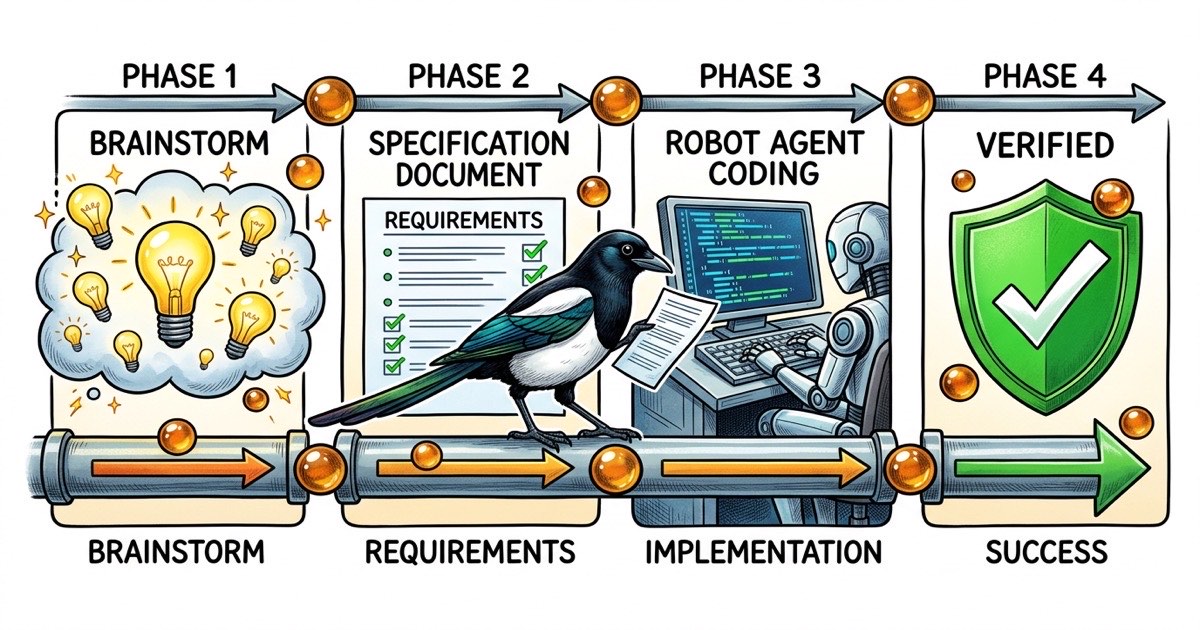
Le developpement spec-first est un cycle de vie en quatre phases. Chaque phase produit un artefact concret. Chaque transition a une condition de passage claire. La methodologie fonctionne avec tout agent de codage IA, mais les exemples de cet article utilisent Claude Code parce que c'est la que la communaute itere le plus vite.
Phase 1 : Brainstorm
Vous et l'agent (ou vous seul) explorez l'espace du probleme. Quelles sont les contraintes ? Quelles approches existent ? Quels sont les compromis ? C'est conversationnel. Vous ne vous engagez sur rien. Vous cartographiez le terrain.
La condition de passage : vous avez une approche preferee et pouvez articuler pourquoi celle-ci plutot que les alternatives.
Le brainstorm avec Claude Code est precieux parce que l'agent a une large connaissance des patterns et librairies. L'erreur est de sauter du brainstorm directement au code. Le brainstorm fait emerger des options. Il ne choisit pas entre elles. C'est vous qui choisissez.
Phase 2 : Spec
Vous ecrivez la decision. C'est le contrat contre lequel l'agent implementera. Une spec n'est pas une user story, pas un ticket Jira, pas un paragraphe de prose. C'est un document structure avec :
- Enonce du probleme : ce qui est casse ou manquant, en termes concrets
- Approche proposee : la solution choisie lors de la phase de brainstorm
- Fichiers concernes : quels fichiers l'agent doit toucher (et implicitement, lesquels il ne doit pas)
- Criteres d'acceptation : conditions testables qui definissent "termine"
- Hors perimetre : ce que l'agent doit explicitement eviter
Les criteres d'acceptation sont l'element le plus important. Chacun doit etre une action concrete avec un resultat observable. "L'authentification devrait fonctionner" n'est pas un critere. "Soumettre des identifiants valides retourne un 200 avec un token de session ; soumettre des identifiants invalides retourne un 401 sans token" en est un.
La section hors perimetre empeche le gold-plating. Sans elle, les agents "amelioreront" du code adjacent, refactoriseront des fichiers qu'ils ont remarques desordonnees, ou ajouteront des fonctionnalites qui semblent liees. Chaque minute que l'agent passe sur du travail non demande est une minute que vous passez a revoir du travail non demande.
La condition de passage : quelqu'un qui n'etait pas au brainstorm pourrait lire cette spec et construire la bonne chose.
Phase 3 : Implementation
L'agent execute contre la spec. Pas contre une conversation. Pas contre un souvenir de ce que vous avez discute. Contre un document concret avec des criteres testables.
Avant d'ecrire du code, l'agent produit un plan : une liste numerotee des changements qu'il compte faire, quels fichiers il modifiera et comment il verifiera le resultat. Ce plan est un checkpoint de deux minutes. Vous le lisez, confirmez qu'il correspond a votre intention et donnez le feu vert a l'implementation. Ou vous detectez un malentendu et le corrigez. Dans les deux cas, vous avez investi deux minutes au lieu de vingt.
Le pattern plan-avant-code n'est pas de la bureaucratie. C'est l'intervention individuelle a plus fort levier dans tout le workflow. La plupart des erreurs d'implementation ne sont pas des erreurs de codage. Ce sont des erreurs de comprehension : l'agent a mal compris la spec. Detecter une erreur de comprehension dans un plan coute deux minutes. La detecter dans un diff de 400 lignes coute vingt. La detecter en production coute une journee.
La condition de passage : l'agent a publie un rapport de completion avec des affirmations specifiques sur ce qui a ete construit et comment cela a ete verifie.
Phase 4 : Verification
Vous ou un processus QA confirmez l'implementation contre la spec. Pas "est-ce que ca a l'air correct ?" mais "est-ce que ca satisfait chaque critere d'acceptation ?"
La verification est mecanique. Vous prenez chaque critere de la spec, executez le test (lancer une commande, ouvrir un navigateur, declencher un evenement) et enregistrez le resultat : passe ou echoue. Les criteres qui echouent retournent en Phase 3. La verification est documentee aux cotes de l'implementation pour que quiconque lira la tache dans six mois puisse voir exactement ce qui a ete teste.
La condition de passage : chaque critere d'acceptation a un resultat passe/echoue enregistre.
Voila le cycle de vie complet. Quatre phases, quatre artefacts (justification de l'approche, spec, plan d'implementation, registre de verification), quatre conditions de passage. Les phases sont sequentielles mais legeres. Pour une fonctionnalite de taille moyenne, les phases 1 et 2 prennent 15-20 minutes. La phase 3 prend le temps de l'implementation. La phase 4 prend 5-10 minutes.
Pourquoi c'est plus important avec les agents qu'avec les humains
Chaque argument pour ecrire des specs est anterieur a l'IA. "Ecrivez les exigences avant le code" est un conseil qui existe depuis avant la naissance de la plupart d'entre nous. Alors pourquoi presenter cela comme specifique au developpement assiste par IA ?
Parce que les agents changent la fonction de cout.
Un developpeur humain qui recoit une exigence vague s'arretera et posera des questions. "Tu voulais dire auth par mot de passe ou SSO ?" "Ca doit fonctionner sur mobile ?" "Que se passe-t-il quand le token expire ?" Chaque question est un mini-checkpoint qui pousse l'implementation vers la bonne cible. Le cout d'une spec vague avec un developpeur humain, c'est quelques fils Slack et peut-etre un apres-midi de retravail.
Un agent qui recoit une exigence vague ne s'arretera pas. Il prendra chaque decision ambigue silencieusement, s'engagera sur une approche et vous presentera une implementation terminee. Le cout d'une spec vague avec un agent, c'est une implementation terminee qui peut etre entierement fausse, plus le temps que vous passez a decouvrir qu'elle est fausse, plus le temps que vous passez a la refaire.
L'asymetrie est frappante. Les agents sont plus rapides a l'execution et moins bons en jugement que les developpeurs humains. Chaque ambiguite dans la spec est un appel au jugement, et chaque appel au jugement que l'agent fait sans guidance est un pile ou face sur le fait que le resultat correspond a votre intention. Une spec elimine les piles ou face.
Il y a une seconde raison, plus subtile. Les agents ne contestent pas. Un ingenieur senior qui recoit une mauvaise spec dira "ca n'a pas de sens a cause de X." Un agent implementera fidelement une mauvaise spec et produira un output fidelement errone. Le developpement spec-first vous oblige a eprouver votre propre reflexion avant de la remettre a une entite qui l'executera sans poser de questions. La spec n'est pas que pour l'agent. Elle est pour vous.