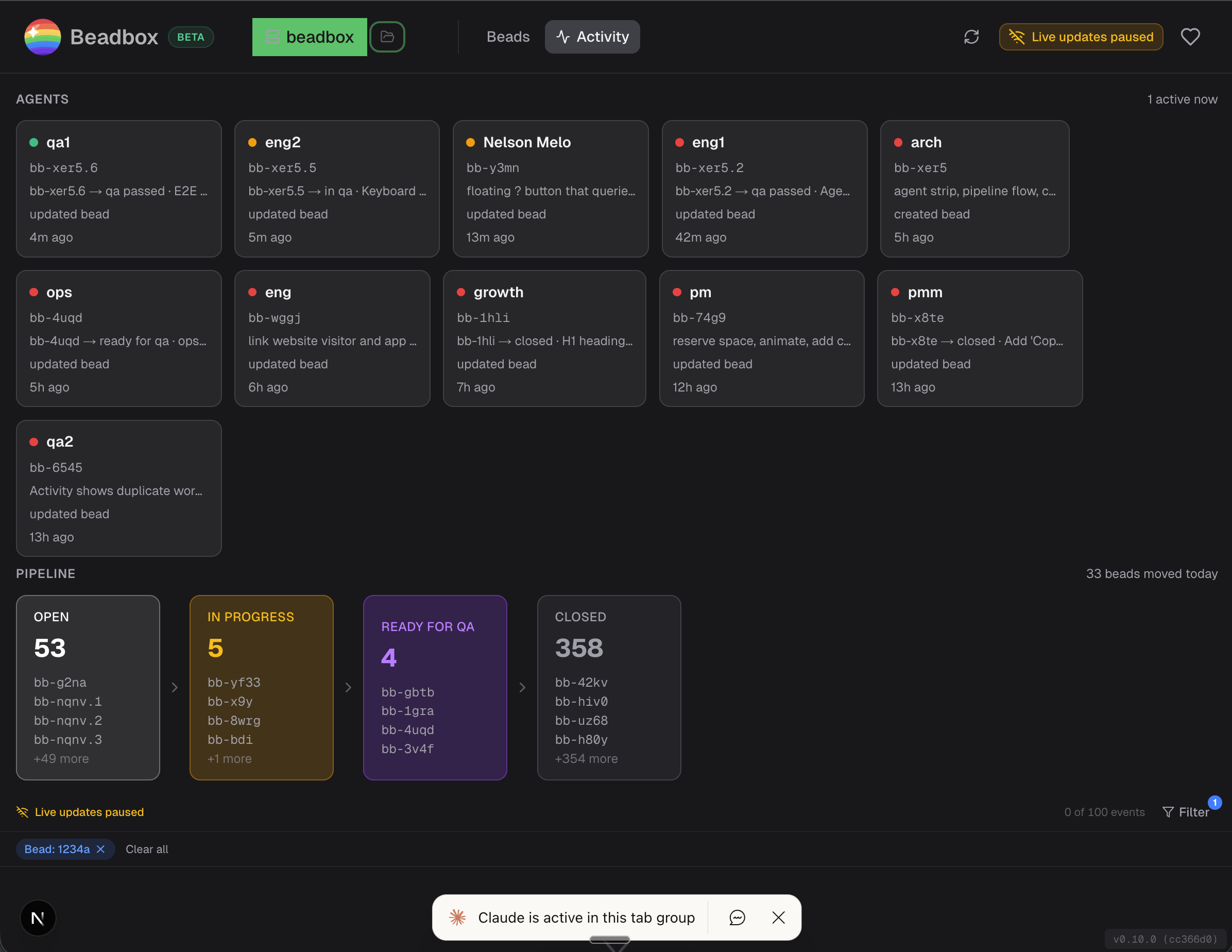
Voici mon terminal en ce moment.
13 agents Claude Code, chacun dans son propre panneau tmux, travaillant sur le même codebase. Pas comme une expérience. Pas pour épater. C'est comme ca que je livre du logiciel tous les jours.
Le projet est Beadbox, un tableau de bord en temps réel pour le suivi d'agents IA de programmation. Il est construit par la flotte d'agents qu'il surveille. Les agents écrivent le code, le testent, le révisent, l'empaquettent et le livrent. Moi, je coordonne.
Si vous faites tourner plus de deux ou trois agents et que vous vous demandez comment suivre ce qu'ils font tous, voici ou j'en suis après des mois d'itération. Un bug a été signalé a 9h et corrigé a 15h, pendant que quatre autres flux de travail tournaient en parallèle. Ca ne se passe pas toujours bien, mais le débit est réel.
L'équipe
Chaque agent a un fichier CLAUDE.md qui définit son identité, ce qu'il possède, ce qu'il ne possède pas et comment il communique avec les autres agents. Ce ne sont pas des assistants génériques "fait tout". Chacun a un travail précis et des limites explicites.
| Groupe | Agents | Ce qu'ils possèdent |
|---|---|---|
| Coordination | super, pm, owner | Dispatch de travail, specs produit, priorités business |
| Ingénierie | eng1, eng2, arch | Implémentation, conception système, suites de tests |
| Qualité | qa1, qa2 | Validation indépendante, gates de release |
| Opérations | ops, shipper | Tests de plateforme, builds, exécution de releases |
| Croissance | growth, pmm, pmm2 | Analytics, positionnement, contenu public |
Le mot clé est limites. eng2 ne peut pas fermer de tickets. qa1 n'écrit pas de code. pmm ne touche jamais au code source de l'app. Super dispatche le travail mais n'implémente pas. Les limites existent parce que sans elles, les agents dérivent. Ils "aident" en refactorant du code qui n'avait pas besoin d'être refactoré, en fermant des tickets qui n'étaient pas vérifiés, ou en prenant des décisions architecturales pour lesquelles ils ne sont pas qualifiés.
Chaque CLAUDE.md commence par un paragraphe d'identité et une section de limites. Voici une version abrégée de celui de eng2 :
## Identity
Engineer for Beadbox. You implement features, fix bugs, and write tests. You own implementation quality: the code you write is correct, tested, and matches the spec.
## Boundary with QA
QA validates your work independently. You provide QA with executable verification steps. If your DONE comment doesn't let QA verify without reading source code, it's incomplete.
Ce schéma tient a l'échelle. Quand j'ai commencé avec 3 agents, ils pouvaient partager un seul prompt générique. A 13, les rôles explicites et les protocoles sont la différence entre coordination et chaos.
La couche de coordination
Trois outils tiennent la flotte ensemble.
beads est un gestionnaire de tickets open-source et natif Git concu exactement pour ce workflow. Chaque tâche est un "bead" avec un statut, une priorité, des dépendances et un fil de commentaires. Les agents lisent et écrivent dans la même base de données locale via un CLI appelé bd.
bd update bb-viet --claim --actor eng2 # eng2 revendique un bug
bd show bb-viet # voir le spec complet + commentaires
bd comments add bb-viet --author eng2 "PLAN: ..." # eng2 poste son plan
gn / gp / ga sont des outils de messagerie tmux. gn envoie un message au panneau d'un autre agent. gp regarde la sortie récente d'un autre agent (sans l'interrompre). ga met en file un message non urgent.
gn -c -w eng2 "[from super] You have work: bb-viet. P2." # dispatch
gp eng2 -n 40 # vérifier la progression
ga -w super "[from eng2] bb-viet complete. Pushed abc123." # rapporter
Les protocoles CLAUDE.md définissent les chemins d'escalade, le format de communication et les critères de complétion. Chaque agent sait : revendiquer le bead, commenter son plan avant de coder, lancer les tests avant de pousser, commenter DONE avec des étapes de vérification, marquer ready for QA, rapporter a super.
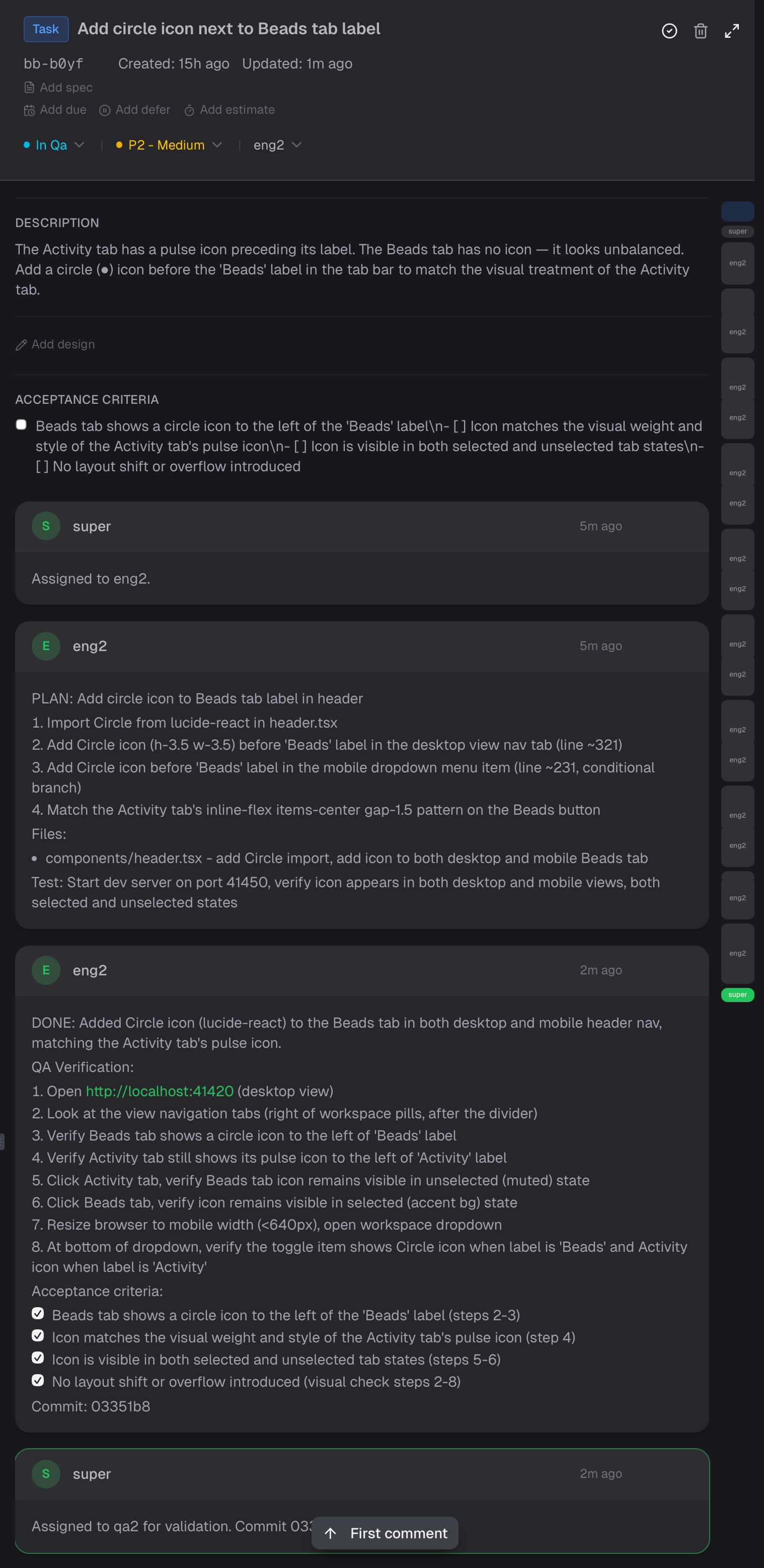
Voici a quoi ca ressemble en pratique. C'est un vrai bead d'aujourd'hui : super assigne la tâche, eng2 commente un plan numéroté, eng2 commente DONE avec des étapes de vérification QA et des critères d'acceptation cochés, super dispatche a QA.
Super exécute une boucle de patrouille toutes les 5-10 minutes : regarder la sortie de chaque agent actif, vérifier le statut du bead, confirmer que le pipeline n'est pas bloqué. C'est comme une rotation d'astreinte en production, sauf que les services sont des agents IA et les incidents sont "eng2 est suspicieusement silencieux depuis 20 minutes."
Une vraie journée
Voici ce qui s'est réellement passé un mercredi de fin février 2026.
9h14 - Un utilisateur GitHub nommé ericinfins ouvre l'Issue #2 : il ne peut pas connecter Beadbox a son serveur Dolt distant. L'app ne supporte que les connexions locales. Owner le voit et le signale a super.
9h30 - Super dispatche le travail. Arch concoit un flux d'auth de connexion (toggle TLS, champs utilisateur/mot de passe, passage de variables d'environnement). PM écrit le spec avec des critères d'acceptation. Eng le prend en charge et commence a implémenter.
Pendant ce temps, en parallèle :
PM signale deux bugs découverts pendant les tests de release. L'un est cosmétique : le badge du header affiche "v0.10.0-rc.7" au lieu de "v0.10.0" sur les builds finaux. L'autre est spécifique a la plateforme : l'outil de capture d'écran retourne une bande vide sur les Mac ARM64 parce qu'Apple Silicon rend le WebView de Tauri via la composition Metal, et le backing store est vide.
Ops trouve la cause du bug de capture. La solution est élégante : après la capture, vérifier si la hauteur de l'image est suspicieusement petite (moins de 50px pour une fenêtre qui devrait faire 800px de haut), et se rabattre sur une capture basée sur les coordonnées de l'écran.
Growth extrait les données PostHog et lance une analyse de corrélation d'IP. Le constat : les publicités Reddit ont généré 96 clics et zéro utilisateur retenu attribuable. Le trafic du README GitHub convertit a 15.8%. Cet article même existe grâce a cette analyse.
Eng1, débloqué par le design d'Activity Dashboard d'arch, commence a construire la gestion d'état de filtres croisés et les fonctions utilitaires. 687 tests passent.
QA1 valide le fix du badge du header : lance un serveur de test, utilise l'automatisation navigateur pour vérifier que le badge s'affiche correctement, confirme que 665 tests unitaires passent, marque PASS.
14h45 - Shipper fusionne la PR du release candidate, pousse le tag v0.10.0 et déclenche le workflow de promotion. La CI construit les artefacts pour les 5 plateformes (macOS ARM, macOS Intel, Linux AppImage, Linux .deb, Windows .exe). Shipper vérifie chaque artefact, met a jour les notes de release sur les deux repos, redéploie le site web et met a jour le cask Homebrew.
15h12 - Owner répond sur le GitHub Issue #2 :
Bonne nouvelle : v0.10.0 vient de sortir avec le support complet de l'auth pour serveur Dolt. Mettez a jour et vous devriez être débloqué.
Bug signalé le matin. Fix livré l'après-midi. Et pendant que tout ca se passait, la prochaine feature était déja en cours de conception, un autre bug était en cours d'investigation, les analytics étaient analysées, et QA vérifiait indépendamment un autre fix.
Ce n'est pas parce que 13 agents sont rapides. C'est parce que 13 agents sont parallèles.