Vous avez une fonctionnalite qui necessite trois choses en meme temps. Vous pouvez lancer des sous-agents dans une seule session Claude Code et les laisser travailler en parallele. Ou vous pouvez decouper le travail en trois taches independantes, confier chacune a un agent separe dans son propre panneau tmux, et les laisser tourner sans qu'ils se connaissent.
Les deux approches parallelisent le travail. Elles resolvent des problemes differents. Choisissez la mauvaise et vous brulerez soit de la fenetre de contexte en overhead de coordination, soit vous creerez des conflits de merge plus longs a resoudre que la tache initiale.
Voici le cadre de decision que j'utilise chaque jour en faisant tourner 13 agents Claude Code sur la meme codebase. Ce n'est pas theorique. C'est le resultat d'avoir fait suffisamment d'erreurs pour savoir ou se trouve la frontiere.
Deux types de parallelisme
Claude Code propose deux facons distinctes d'executer du travail de maniere concurrente.
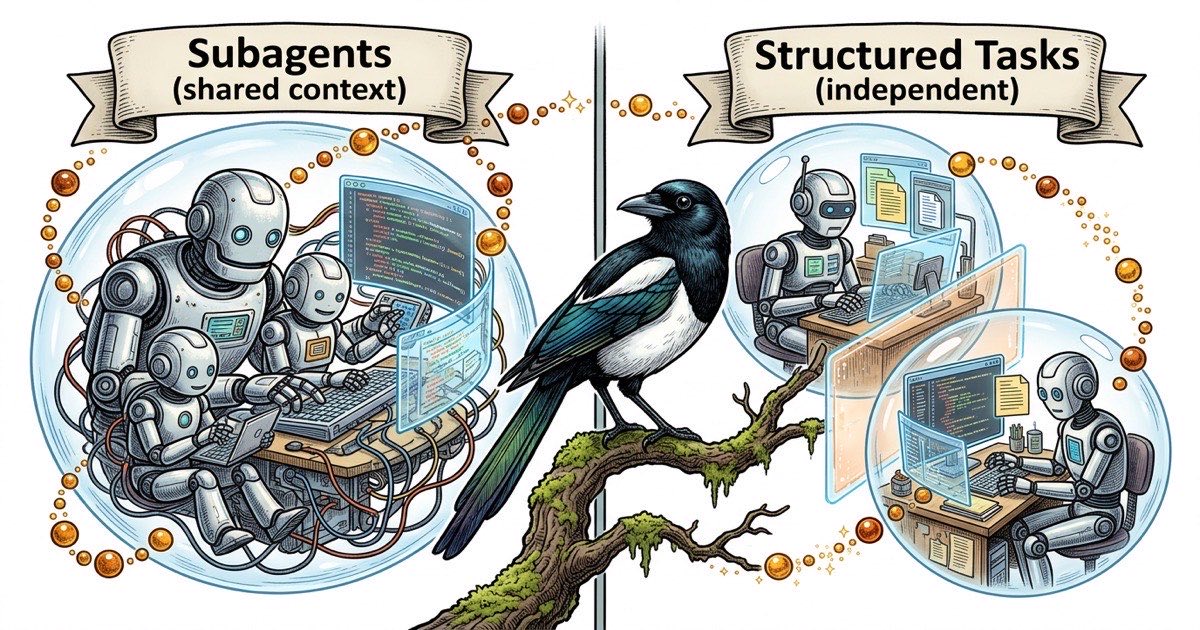
Les sous-agents sont des processus enfants lances au sein d'une seule session Claude Code. L'agent parent demarre plusieurs sous-agents, chacun s'attaque a une partie du probleme, puis rassemble les resultats. Ils partagent le meme repertoire de travail et le contexte du parent. Pensez a eux comme des threads dans un seul processus.
Parent agent
├── Subagent A: "Search lib/ for all usages of parseConfig"
├── Subagent B: "Search server/ for all usages of parseConfig"
└── Subagent C: "Search components/ for all usages of parseConfig"
Les agents separes tournent dans des sessions Claude Code independantes, generalement dans des panneaux tmux distincts. Chacun a sa propre fenetre de contexte, son propre fichier d'identite CLAUDE.md et sa propre vue de la codebase. Ils ne partagent pas de memoire. Ils communiquent a travers des artefacts : commentaires de taches, mises a jour de statut, code commite. Pensez a eux comme des processus separes sans etat partage.
tmux pane 1: eng1 agent → "Build the REST endpoint"
tmux pane 2: eng2 agent → "Build the React component"
tmux pane 3: qa1 agent → "Write integration tests for both"
Le modele mental compte parce qu'il determine comment le travail circule entre les unites. Les sous-agents peuvent renvoyer des donnees au parent a moindre cout. Les agents separes transmettent des donnees via le systeme de fichiers, git ou un gestionnaire de taches externe.
Quand les sous-agents gagnent
Utilisez les sous-agents quand le travail partage un etat et que les resultats doivent converger.
Recherche en parallele. Vous devez parcourir cinq repertoires a la recherche d'un pattern, lire trois fichiers de documentation et synthetiser les resultats en une recommandation. Les sous-agents peuvent chacun prendre un chemin de recherche, retourner des resultats, et le parent peut les combiner sans overhead de serialisation.
Transformations independantes sur les memes donnees. Vous refactorisez un module et devez mettre a jour les definitions de types, les tests et la documentation en un seul changement coherent. Chaque sous-agent gere un fichier, mais le parent s'assure de la coherence puisqu'il voit les trois resultats avant de commiter.
Exploration rapide. Vous debuguez et devez verifier le git log, la sortie des tests et la config runtime simultanement. Les sous-agents peuvent collecter les trois en parallele et le parent synthetise un diagnostic.
Le pattern : distribuer, rassembler, agir sur le resultat combine. Si votre parallelisme se termine par le parent devant raisonner sur tous les outputs ensemble, les sous-agents sont le bon outil.
Ou les sous-agents echouent : tout ce qui prend plus de quelques minutes par branche, tout ce qui modifie des fichiers dans des chemins superposes, ou tout ce qui necessite une verification independante. Les sous-agents partagent un repertoire de travail, donc deux sous-agents ecrivant dans le meme fichier corrompront mutuellement leur travail. Et puisqu'ils partagent le contexte, un sous-agent de longue duree consomme la fenetre disponible du parent.
Quand les agents separes gagnent
Utilisez des agents separes quand le travail peut etre verifie independamment et n'a pas besoin d'un contexte partage pour avoir du sens.
Differents composants de la meme fonctionnalite. "Construire l'endpoint API" et "Construire le frontend qui l'appelle" sont independants jusqu'a l'integration. L'ingenieur API n'a pas besoin du composant React dans son contexte. L'ingenieur frontend n'a pas besoin du schema de base de donnees. Donner a chacun son propre agent avec un CLAUDE.md delimite garde le contexte propre et empeche la complexite d'un agent de contaminer le travail de l'autre.
Des criteres d'acceptation differents. Si la tache A est terminee quand l'endpoint retourne 200 avec la bonne forme JSON, et la tache B est terminee quand le composant affiche les donnees avec les bons etats d'erreur, ce sont des cibles de verification separees. Un agent QA peut valider chacune independamment. Les sous-agents ne peuvent pas etre verifies independamment car ils produisent un output combine.
Du travail qui touche differentes parties de la codebase. Le file ownership est le moyen le plus simple de prevenir les conflits de merge. L'agent A possede server/, l'agent B possede components/. Aucun n'entre dans le territoire de l'autre. Si vous essayez avec des sous-agents, le parent devrait gerer le file locking, ce qui annule l'interet du parallelisme.
Des taches avec des horizons de temps differents. Une tache prend 10 minutes, l'autre 2 heures. Avec les sous-agents, le parent attend l'enfant le plus lent. Avec des agents separes, la tache courte se termine, est verifiee et shippee pendant que la tache longue tourne encore.
Le pattern : lancer, oublier, verifier separement. Si chaque morceau de travail tient seul et peut etre verifie seul, les agents separes avec des taches structurees sont plus propres.
Le probleme du transfert
Le veritable point de decision se resume aux transferts.
Les transferts de sous-agents sont peu couteux. L'enfant renvoie des donnees au parent dans le meme contexte. Pas de serialisation, pas d'ecriture de fichiers, pas d'attente de mise a jour de statut. Le parent lance trois sous-agents, ils retournent trois resultats, le parent a tout ce qu'il faut.
Les transferts entre agents separes sont couteux mais durables. L'agent A termine son travail, commite du code, met a jour un statut de tache et commente ce qu'il a fait. L'agent B capte ce signal (soit via un coordinateur, soit en interrogeant le gestionnaire de taches) et commence son travail dependant. L'overhead est reel : vous avez besoin d'un systeme de taches, d'un protocole de statut et d'un moyen pour que les agents decouvrent ce que d'autres agents ont fait.
La regle generale : si le travail necessite plus d'un transfert entre les unites paralleles, utilisez les sous-agents. Pour un simple fan-out-and-gather, les sous-agents sont plus simples. Si l'output de l'agent A est l'input de l'agent B, qui devient l'input de l'agent C, le cout de coordination des agents separes est justifie parce que chaque transfert produit un artefact verifie et commite qui ne sera pas perdu si un agent plante ou atteint une limite de contexte.
Un exemple concret. Vous devez :
- Trouver tous les endpoints API qui retournent des donnees utilisateur
- Ajouter du rate limiting a chacun
- Ecrire des tests pour les nouveaux rate limits
- Mettre a jour la documentation API
Les etapes 1 et 2 sont fortement couplees. Les resultats de recherche (etape 1) alimentent directement la modification (etape 2). Un sous-agent gere la recherche ; le parent applique les changements. C'est un pattern de sous-agent.
Les etapes 3 et 4 sont independantes l'une de l'autre mais dependent de l'etape 2. Les tests ont besoin du code reel de l'endpoint. La documentation a besoin de la forme finale de l'API. Ce sont des taches separees pour des agents separes, chacune avec ses propres criteres d'acceptation, chacune verifiable independamment.