Vous avez commence avec un seul serveur MCP. L'acces aux fichiers, pour que votre agent Claude Code puisse lire et ecrire votre projet. Raisonnable.
Puis vous avez ajoute la recherche web. Puis GitHub. Puis un outil de base de donnees pour que l'agent puisse interroger votre schema directement. Puis Slack, parce que l'agent devait verifier un fil de discussion pour les exigences. Puis un outil de documentation pour votre wiki interne.
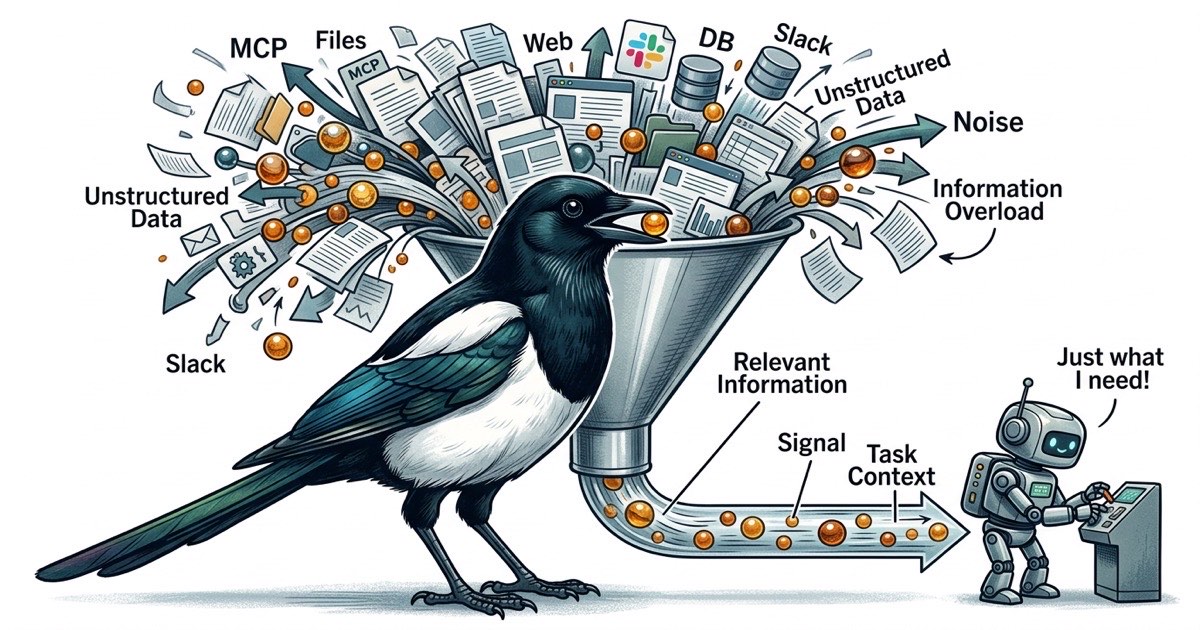
Six serveurs MCP. Chacun enregistre des schemas d'outils dans le contexte de l'agent. Chacun elargit la surface de ce que l'agent pourrait faire, ce qui signifie plus de tokens depenses en descriptions d'outils et plus d'occasions pour l'agent de s'eloigner de sa tache.
Votre agent ecrit toujours du bon code. Mais il l'ecrit plus lentement, et les resultats sont devenus moins previsibles. Vous ne l'imaginez pas. La fenetre de contexte est le goulot d'etranglement, et vous la remplissez avec de la plomberie.
Le probleme de l'accumulation
Les serveurs MCP sont puissants. Le Model Context Protocol donne a Claude Code l'acces a des systemes externes, et chaque integration resout veritablement un probleme. L'acces aux fichiers permet a l'agent de lire votre codebase. La recherche web lui permet de consulter de la documentation. L'integration GitHub lui permet de verifier le statut des PRs.
Le probleme commence quand vous resolvez chaque besoin de l'agent en ajoutant un autre MCP.
L'agent doit verifier le schema de la base de donnees ? Ajoutez un MCP Postgres. L'agent doit lire une page Confluence ? Ajoutez un MCP Confluence. L'agent doit poster un message Slack ? Ajoutez un MCP Slack. Chacun est justifie individuellement. Collectivement, ils creent un probleme difficile a remarquer tant que la qualite des resultats ne chute pas.
Chaque serveur MCP enregistre ses outils dans le contexte de la conversation. Un MCP d'acces aux fichiers peut enregistrer 5 a 10 outils. Un MCP de base de donnees en enregistre d'autres. Un MCP GitHub en ajoute davantage. Quand vous avez six serveurs MCP, l'agent porte des dizaines de definitions d'outils dans sa fenetre de contexte avant de lire une seule ligne de votre code.
Ces definitions d'outils ne sont pas gratuites. Elles consomment des tokens. Et surtout, elles rivalisent pour l'attention de l'agent. Quand un agent a 40 outils disponibles, chaque point de decision devient une question de branchement : dois-je utiliser l'outil fichier, l'outil de recherche, l'outil base de donnees ou l'outil GitHub ? L'agent depense du budget cognitif a decider comment obtenir l'information au lieu d'utiliser l'information pour resoudre votre probleme.
Le contexte est fini. L'attention est plus rare.
La fenetre de contexte de Claude Code est grande. Cela cree une illusion dangereuse : que vous pouvez continuer a ajouter des informations sans consequence.
En pratique, les performances de l'agent se degradent bien avant que la fenetre de contexte ne se remplisse. Le probleme n'est pas la capacite. C'est le rapport signal-bruit. Un agent avec une fenetre de contexte de 200K tokens performe mieux avec 50K tokens d'information ciblee et pertinente qu'avec 150K tokens ou les elements pertinents sont disperses parmi des schemas d'outils, des reponses d'API et des contenus de fichiers tangentiels.
C'est le meme probleme que les humains rencontrent avec trop d'onglets de navigateur. L'information est techniquement disponible. La trouver prend plus de temps que prevu. On finit par relire des choses qu'on a deja vues parce que le contexte pertinent a ete chasse de la memoire de travail par le bruit.
Pour les agents, cela se manifeste par :
Les terriers de lapin. L'agent a un outil de base de donnees, donc il interroge le schema. Le schema est interessant, donc il interroge des donnees. Les donnees revelent quelque chose d'inattendu, donc il poursuit son investigation. Vingt minutes plus tard, vous avez une analyse approfondie du contenu de votre base de donnees et zero progres sur la fonctionnalite demandee.
La confusion d'outils. Avec de nombreux outils disponibles, l'agent choisit parfois le mauvais. Il utilise la recherche web pour trouver de la documentation qui est deja dans un fichier local. Il interroge la base de donnees quand la reponse est dans la description de la tache. Chaque mauvais choix d'outil gaspille des tokens et introduit du bruit.
La dilution du focus. L'attention de l'agent est une ressource finie a chaque generation. Quand le contexte contient des schemas d'outils pour l'acces aux fichiers, la recherche web, les requetes de base de donnees, les operations GitHub, les messages Slack et les consultations de wiki, l'agent traite tout cela avant de traiter votre requete reelle. La tache entre en competition avec l'outillage pour la priorite cognitive.
Le contexte borne : l'alternative a la proliferation d'outils
La reponse reflexe a "mon agent a besoin de l'information X" est de donner a l'agent un outil qui recupere X. Mais il y a une autre approche : mettre X dans la tache.
C'est le patron du contexte borne. Au lieu de donner aux agents l'acces a tout et d'esperer qu'ils trouvent ce qui est pertinent, vous donnez a chaque agent une tache qui contient tout ce dont il a besoin pour terminer le travail. L'agent ne cherche pas le contexte. Le contexte lui est livre.
La difference est structurelle. Avec la proliferation de MCPs, le workflow de l'agent ressemble a :
- Lire la tache
- Determiner quelles informations manquent
- Utiliser divers outils pour collecter ces informations
- Synthetiser les informations
- Faire le travail reel
Avec le contexte borne, ca ressemble a :
- Lire la tache (qui contient tout le contexte necessaire)
- Faire le travail reel
Les etapes 2 a 4 du premier workflow ne sont pas juste du surcharge. C'est la que les choses derapent. L'agent collecte trop d'information, ou la mauvaise information, ou se laisse distraire par des donnees interessantes mais non pertinentes. Chaque invocation d'outil est un detour potentiel.
Le contexte borne ne signifie pas que les agents ne peuvent pas utiliser d'outils. L'acces aux fichiers reste necessaire pour lire et ecrire du code. Mais cela signifie que le contexte informationnel (quoi construire, pourquoi, quels fichiers, quels sont les criteres d'acceptation) vit dans la tache, pas dans un outil que l'agent doit interroger.
Structurer les taches comme conteneurs de contexte
Une tache qui fonctionne comme conteneur de contexte est differente d'un ticket Jira ou d'un issue GitHub classique. Elle est autonome. Un agent qui la lit devrait avoir tout ce qu'il lui faut pour commencer a travailler sans interroger de systemes externes.
Voici a quoi cela ressemble en pratique :
Title: Add rate limiting to /api/search endpoint
Description:
The /api/search endpoint currently has no rate limiting.
Add a token bucket rate limiter at 100 requests/minute per IP.
Files to modify:
- server/middleware/rate-limit.ts (create new)
- server/routes/search.ts (apply middleware)
- server/config.ts (add RATE_LIMIT_RPM env var)
Acceptance criteria:
- Requests beyond 100/min from same IP return 429
- Rate limit resets after 60 seconds
- Config value overridable via environment variable
- Existing tests still pass
Context:
- We use Express middleware pattern (see server/middleware/auth.ts for example)
- The config module uses dotenv (see server/config.ts lines 1-15)
- No Redis available; use in-memory store. This is a single-instance app.
Dependencies: None. This can run independently.
Remarquez ce qui est integre dans la tache. L'agent sait quels fichiers toucher, quel patron suivre, quelles contraintes existent (pas de Redis), et exactement a quoi ressemble "termine." Il n'a pas besoin d'un MCP de base de donnees pour verifier le schema. Il n'a pas besoin d'un outil wiki pour trouver le patron de middleware. Il n'a pas besoin de chercher dans le codebase pour comprendre l'approche de configuration. Tout est dans la tache.
Ecrire des taches de cette facon demande plus d'effort en amont. Un ticket classique pourrait dire "Ajouter le rate limiting au endpoint de recherche" et laisser l'agent decouvrir le reste. Mais ce processus de decouverte est exactement ce qui engendre la proliferation de MCPs : l'agent a besoin d'information, donc vous lui donnez des outils, et les outils consomment du contexte.