Linear es rápido. Hay que reconocerlo. Invirtieron mucho en rendimiento percibido, y para la mayoría de equipos es el mejor issue tracker SaaS disponible. Pero "mejor SaaS" viene con restricciones que algunos desarrolladores no pueden aceptar: tus datos viven en los servidores de otro, tu workflow se adapta a sus opiniones, y cada interacción paga un impuesto de ida y vuelta por red.
Este post es para desarrolladores que han chocado con esas paredes. Quizás gestionas flotas de agentes IA que crean 50 issues por hora. Quizás trabajas air-gapped u offline-first. Quizás simplemente no quieres una pantalla de login entre tú y tus issues. Aquí está lo que aprendimos construyendo Beadbox, un issue tracker de escritorio nativo que mantiene todo local.
Ve directo a lo que te interesa:
Por qué los desarrolladores buscan alternativas a Linear
La respuesta habitual es "Linear es demasiado opinionado." Es cierto pero impreciso. Linear impone ciclos, estructuras de equipo y estados de workflow que asumen que eres un equipo de producto entregando en cadencias de dos semanas. Si ese eres tú, Linear es genial. Si eres un desarrollador solo coordinando agentes IA, o un equipo de investigación con patrones de iteración no estándar, o un grupo DevOps que necesita issues vinculados a commits de git en lugar de hilos de Slack, las opiniones de Linear se convierten en fricción.
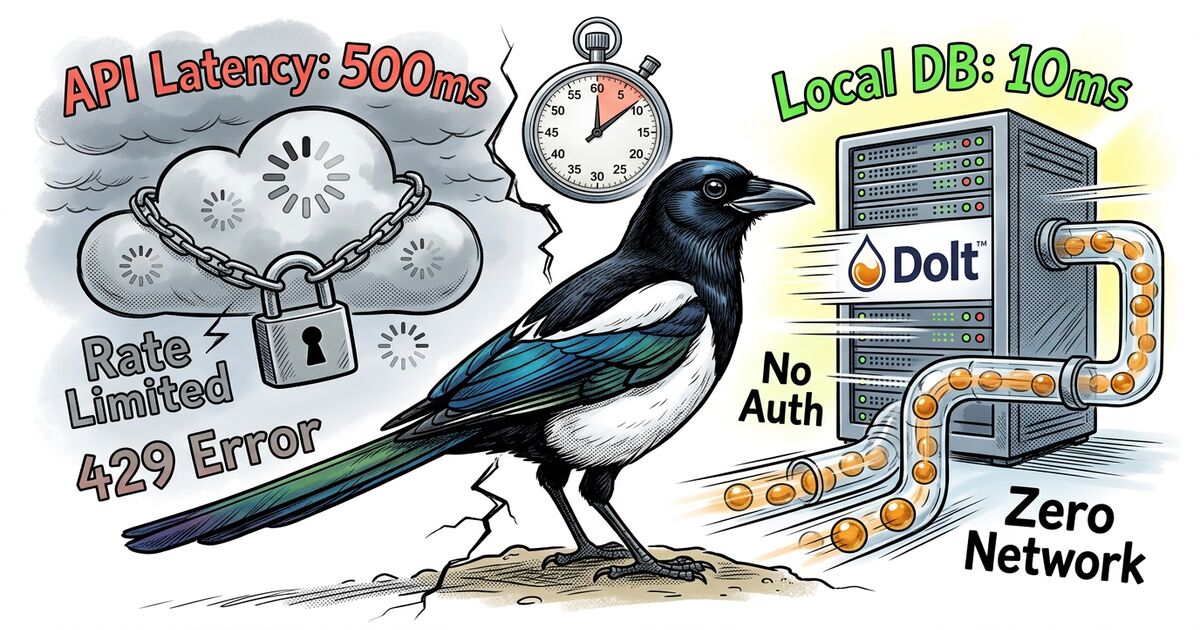
El problema más profundo es arquitectónico. Linear es un producto SaaS cloud-first. Cada mutación viaja a sus servidores y vuelve. Cada consulta depende de su uptime. Tus datos de issues existen en su base de datos, consultables a través de su API, en sus términos. Para la mayoría de equipos, es un tradeoff aceptable. Para desarrolladores que valoran la soberanía de datos, el acceso offline o la velocidad bruta de consulta en datasets grandes, es un dealbreaker.
Lo que Beadbox no hace
Antes de meternos en lo que Beadbox hace bien, aquí está dónde no es la elección correcta. Saltar esta sección no te ayuda; chocar con estas paredes después de adoptar una herramienta sí duele.
Sin permisos multiusuario ni control de acceso. No hay cuentas de usuario, ni roles, ni restricciones de visibilidad por issue. Cualquiera con acceso al sistema de archivos del directorio .beads/ (o al servidor Dolt) puede leer y escribir todo. Si necesitas restringir quién ve qué, Beadbox no es para ti hoy.
Colaboración en tiempo real limitada. Dos personas pueden trabajar en el mismo set de issues, pero el modelo de colaboración es push/pull (como Git), no cursores en vivo e indicadores de presencia. En modo servidor, Beadbox hace polling cada 3-5 segundos. En modo embebido, la vigilancia del sistema de archivos detecta cambios más rápido (sub-segundo), pero escrituras concurrentes al mismo banco Dolt desde dos procesos pueden fallar. El patrón seguro es: un escritor a la vez, o usar modo servidor con Dolt manejando la concurrencia.
Sin integraciones con Slack, GitHub, Figma u otras herramientas SaaS. El punto de extensión es el CLI bd y scripts shell. Si tu workflow depende de "issue cerrado dispara mensaje en Slack," tendrás que construir ese pegamento tú mismo.
El techo de escala es real pero distante. Probamos contra datasets de 10K y 20K issues (ver benchmarks abajo). Funcionan bien. No hemos hecho pruebas de estrés con 100K+ issues. Si eres una organización grande generando cientos de miles de issues por año, este no es territorio probado.
Sin acceso para stakeholders no técnicos. No hay portal web, ni visor de invitados, ni URL de dashboard compartible. Beadbox es una app de escritorio que lee un banco local. Mostrar progreso a un PM que no usa tu máquina significa compartir pantalla o un script bd que genere un reporte.
Cómo funciona Beadbox (la versión de 30 segundos)
Antes de que los benchmarks tengan sentido, aquí está la arquitectura:

Modo embebido: El banco Dolt vive en .beads/ en tu sistema de archivos. Sin proceso de servidor, sin demonio. El CLI bd lee y escribe directamente. Beadbox detecta cambios vía fs.watch() con debounce de 250 ms y transmite por WebSocket a la UI. Este es el camino de configuración cero.
Modo servidor: Un proceso dolt sql-server corre por separado (local o LAN). El CLI bd se conecta por protocolo MySQL. Beadbox hace polling al servidor cada 3-5 segundos para cambios en lugar de vigilar el sistema de archivos. Este modo soporta múltiples escritores concurrentes.
Cada operación que la GUI realiza pasa por el CLI bd. Beadbox nunca toca el banco directamente. Si bd show y Beadbox no concuerdan, es un bug en Beadbox.
Rendimiento: benchmarks reales en un dataset de 10K issues
El CLI de beads publica benchmarks que puedes reproducir en tu propio hardware. Aquí están números reales de un M2 Pro corriendo la suite de benchmarks Go contra una base Dolt de 10.000 issues:
| Operación |
Tiempo |
Memoria |
Dataset |
| Filtrar trabajo listo (issues desbloqueados) |
30ms |
16,8 MB |
10K issues |
| Búsqueda (todos abiertos, sin filtro) |
12,5ms |
6,3 MB |
10K issues |
| Crear issue |
2,5ms |
8,9 KB |
10K issues |
| Actualizar issue (cambio de status) |
18ms |
17 KB |
10K issues |
| Detección de ciclos (cadena lineal de 5K) |
70ms |
15 KB |
5K deps |
| Cierre masivo (100 issues) |
1,9s |
1,2 MB |
Escrituras secuenciales |
| Merge de sincronización (10 creates + 10 updates) |
29ms |
198 KB |
Operación batch |
Estos son benchmarks a nivel CLI: el tiempo que tarda bd en leer o escribir en la base Dolt local. La UI de Beadbox añade overhead de renderizado encima. Nuestros objetivos de diseño para el stack completo (llamada CLI + render React + propagación WebSocket) son:
| Operación UI |
Objetivo de diseño |
| Render de árbol épico (100+ issues) |
< 500ms |
| Aplicar/limpiar filtro |
< 200ms |
| Cambio de workspace |
< 1 segundo |
| Propagación de actualización en tiempo real (embebido) |
< 2 segundos |
| Arranque en frío a usable |
< 5 segundos |
No publicamos benchmarks contra Linear u otros trackers porque no hemos corrido comparaciones controladas, y números seleccionados a dedo no serían honestos. Lo que sí podemos decir: todo el flujo de datos es local. No hay salto de red entre hacer clic en un filtro y ver los resultados. Si eso importa depende de tu baseline. Si Linear se siente suficientemente rápido para tu tamaño de dataset y ubicación, probablemente lo es. Si has sentido el lag en un backlog de 500 issues desde el Wi-Fi de un hotel de conferencia, conoces el problema que estos números abordan.
Para reproducir: clona beads, ejecuta go test -tags=bench -bench=. -benchmem ./internal/storage/dolt/..., y compara con tu hardware. Los datasets cacheados aterrizan en /tmp/beads-bench-cache/.
Profundidad de integración Git: más allá de vincular commits a issues
La mayoría de los issue trackers tratan la integración con Git como una casilla de verificación: menciona un ID de issue en un mensaje de commit y aparece un enlace en el issue. Es útil pero superficial.
Beadbox está construido sobre beads, un issue tracker donde la semántica de Git es la capa de almacenamiento, no una integración añadida. Dolt, la base de datos subyacente, implementa el modelo de datos de árbol merkle de Git para datos estructurados. Cada cambio de issue es un commit. Cada commit tiene un padre. Obtienes dolt diff, dolt log y dolt merge en tu historial de issues con la misma semántica que usas en código.
Lo que significa en la práctica:
Tu historial de issues es auditable. La base de datos misma es un grafo de commits. Puedes hacer diff entre dos puntos en el tiempo y ver exactamente qué campos cambiaron en qué issues. Esto no es una "feature de log de auditoría" añadida encima. El formato de almacenamiento es el rastro de auditoría.
Las ramas funcionan en issues, no solo en código. Dolt soporta ramas nativamente. Puedes hacer branch en tu base de issues para experimentar con una reorganización, luego mergearla o descartarla.
La sincronización es push/pull, no llamadas API. La colaboración multimáquina funciona como git push y git pull. Sin tokens API, sin webhooks, sin flujos OAuth. Apunta tu remote de Dolt a un servidor (o DoltHub) y haz push. La otra máquina hace pull.
Una nota sobre conflictos: Dolt usa three-way merge, igual que Git. Si dos personas editan campos diferentes en el mismo issue, el merge se resuelve automáticamente. Si dos personas editan el mismo campo en el mismo issue, obtienes un conflicto que requiere resolución manual a través del CLI de Dolt (dolt conflicts resolve). Beadbox aún no tiene UI de resolución de conflictos; manejas los conflictos a nivel dolt. En la práctica, los conflictos son raros cuando cada persona (o agente) trabaja en issues distintos, que es el patrón típico. Pero si tu equipo edita frecuentemente los mismos issues de forma concurrente, este es un punto de fricción que debes conocer. La documentación de merge de Dolt cubre el workflow de resolución en detalle.
Renderizado nativo: por qué incluimos Node.js dentro de Tauri
Linear corre en una pestaña del navegador. También Jira, Asana y todos los demás trackers SaaS. Las pestañas del navegador compiten por memoria, son suspendidas por el SO y renderizan a través de un compositor que añade frames de latencia.
Beadbox corre como una aplicación de escritorio nativa construida con Tauri. Las apps Tauri suelen ser pequeñas (el runtime de Tauri en sí son pocos megabytes) porque usan el WebView nativo del SO en lugar de incluir Chromium. Nuestro bundle es más grande que las apps Tauri típicas con aproximadamente 160 MB, y es un tradeoff deliberado que vale la pena explicar.
84 MB de eso es un runtime Node.js embebido. Usamos una arquitectura sidecar: Tauri lanza un servidor Next.js como proceso hijo, que maneja server-side rendering, server actions y la capa WebSocket para actualizaciones en tiempo real. El WebView de Tauri apunta a este servidor local. Elegimos esto en vez de un backend puro en Rust porque el ecosistema Next.js nos da React Server Components, server actions y velocidad de iteración rápida en la capa de UI. El costo es el tamaño del bundle. Una app Electron equivalente pesaría 400 MB+. Una app pura Rust + Tauri pesaría menos de 10 MB pero habría tardado 3x más en construir y perdería el ecosistema React.
Editor's note (2026-04 update): This architecture description reflects Beadbox v0.24 and earlier. As of v0.25, Beadbox migrated from the Node.js + Next.js sidecar to a compiled Bun binary spawned via tauri-plugin-js, with Vite + TanStack Router replacing Next.js on the UI side. Bundle size and the trade-off math have shifted; the rationale for picking native + sidecar over Electron or pure Rust still holds. See ADR-2008 in the repo for the migration record.
La diferencia práctica respecto a una pestaña del navegador: Beadbox renderiza en un proceso WebView dedicado que no comparte memoria con tus otras 47 pestañas del navegador. Expandir un árbol épico con 100+ issues anidados, aplicar filtros a todo el backlog, cambiar entre workspaces: estas operaciones se sienten cualitativamente diferentes cuando el renderizador no compite por recursos.
Extensión con el CLI, no una API REST
Linear tiene una API GraphQL. Está bien diseñada. Pero extender Linear significa escribir código que habla con sus servidores, se autentica con sus tokens y maneja sus límites de rate.
Beadbox toma un enfoque diferente: el CLI bd es la API. Cada operación que la GUI realiza pasa por bd, la misma herramienta de línea de comandos que usarías en tu terminal.
Aquí hay tres workflows que puedes copiar y pegar hoy:
Actualización masiva de prioridades para un barrido de triaje:
# Poner todos los bugs abiertos en prioridad 1 (crítica)
bd list --status=open --type=bug --json | \
jq -r '.[].id' | \
xargs -I{} bd update {} --priority=1
Generar un resumen diario de estado:
# ¿Qué cambió en las últimas 24 horas?
echo "=== Closed today ==="
bd list --status=closed --json | \
jq -r '.[] | select(.updated > (now - 86400 | todate)) | "\(.id) \(.title)"'
echo "=== Currently blocked ==="
bd blocked --json | \
jq -r '.[] | "\(.id) \(.title) (blocked by: \(.blocked_by | join(", ")))"'
echo "=== Ready to work ==="
bd ready --json | jq -r '.[] | "\(.id) [P\(.priority)] \(.title)"'
Un agente IA crea y reclama trabajo:
# El agente descubre un bug, lo registra y lo reclama
ISSUE_ID=$(bd create \
--title "Fix race condition in auth middleware" \
--type bug \
--priority 1 \
--json | jq -r '.id')
bd update "$ISSUE_ID" --status=in_progress --assignee=agent-3
# ... el agente hace el trabajo ...
bd update "$ISSUE_ID" --status=closed
bd comments add "$ISSUE_ID" --author agent-3 \
"Fixed in commit abc1234. Root cause: mutex not held during token refresh."
Si corres agentes IA de programación (Claude Code, Cursor, Copilot Workspace), ya saben ejecutar comandos CLI. Sin biblioteca cliente, sin danza de autenticación. Solo pipes Unix y scripts shell.
Prueba Beadbox para ver estos workflows visualizados en tiempo real mientras los agentes los ejecutan.
Offline-first no es una feature, es una arquitectura
Algunos trackers cloud ofrecen un "modo offline" que cachea datos recientes y sincroniza al reconectarse. Es una feature añadida a una arquitectura fundamentalmente online. Los modos de fallo son predecibles: caché desactualizado, conflictos de sincronización, operaciones que se encolan en silencio y fallan después.
Beadbox funciona offline porque nunca estuvo online en primer lugar. En modo embebido, toda tu base de issues es un directorio en tu sistema de archivos. Sin proceso de servidor. Sin demonio. Sin socket de red. El CLI bd lee y escribe en ese directorio. Beadbox lo vigila con fs.watch() y renderiza lo que encuentra.
No hay nada que sincronizar porque no hay nada remoto. Si después eliges colaborar, el push/pull de Dolt te da sincronización explícita y visible. Pero el default es local. El default es tuyo.
¿Qué hay de la seguridad? Si estás evaluando Beadbox para entornos air-gapped o sensibles, aquí está la postura concreta:
- Cifrado en reposo: Beadbox no cifra el directorio
.beads/ por sí mismo. Depende del cifrado a nivel de SO (FileVault en macOS, LUKS en Linux, BitLocker en Windows). Si tu modelo de amenaza requiere cifrado por base de datos, este es un hueco.
- Backups: Tu directorio
.beads/ es un directorio normal. cp -r, rsync, Time Machine o dolt push a un remoto funcionan. El historial de commits de Dolt también significa que cambios accidentales pueden revertirse con dolt reset.
- Qué sale de la máquina: En modo embebido, nada. Cero llamadas de red. En la app de escritorio, existen dos conexiones salientes opcionales: API de GitHub para verificar actualizaciones de Beadbox (se puede desactivar en ajustes), y analítica PostHog si aceptas (desactivada por defecto, sin PII recolectada). Ninguna transmite datos de issues.
Para entornos air-gapped, proyectos clasificados o desarrolladores que trabajan en aviones y trenes, esto no es un nice-to-have. Es la única arquitectura que funciona.
Sin la trampa del precio por puesto
Linear cobra $8/month por miembro en el plan Standard. Razonable para un equipo de cinco personas. Menos razonable cuando tu "equipo" incluye 13 agentes IA que necesitan leer y escribir issues.
El modelo por puesto asume equipos estables y de tamaño humano. La ingeniería agéntica rompe esa premisa. Puedes levantar 3 agentes para un bugfix y 13 para un release. Cada uno necesita acceso a la API. En precios SaaS, cada agente es un puesto. Cada puesto es una línea en la factura. El costo escala linealmente con un recurso que estás escalando exponencialmente.
beads es open-source. El CLI es gratuito. No hay tarifa por puesto, ni niveles de uso, ni "contacte a ventas para enterprise." Puedes correr 2 agentes o 200 contra la misma base de datos local y el costo no cambia.
Beadbox (la GUI) es gratis durante la beta. El precio post-beta no está definido, pero no será por puesto. Los agentes no son personas. Cobrar por agente tiene tanto sentido como cobrar por ventana de terminal.
Ecosistema open-source
beads no es un jardín amurallado. El CLI es open-source en github.com/steveyegge/beads, y la comunidad ha construido 30+ herramientas sobre él: reporteadores personalizados, integraciones CI, scripts de orquestación de agentes, extensiones de dashboard y adaptadores de exportación.
Qué significa en la práctica:
Puedes inspeccionar todo. El formato de almacenamiento es Dolt, consultable con SQL estándar. El código fuente del CLI es Go, legible y bifurcable. Si bd create hace algo inesperado, puedes leer el código que lo ejecuta.
Puedes extender sin pedir permiso. Sin proceso de aprobación de marketplace, sin programa de partners, sin negociación de límites de API. Escribe un script shell, un plugin Go o un wrapper Python. La flag --json del CLI en cada comando te da salida estructurada para canalizar hacia lo que construyas.
Tus datos son portables. El push/pull de Dolt permite que tu base de issues viva en cualquier servidor que controles, se sincronice con DoltHub o se quede en tu sistema de archivos para siempre. No hay wizard de exportación porque no hay nada de dónde exportar. Los datos ya son tuyos, en un formato que puedes consultar directamente.
La comunidad construye herramientas específicas para agentes. Los desarrolladores que usan beads diariamente son quienes corren flotas de agentes IA. Las extensiones que construyen resuelven problemas de coordinación de agentes: operaciones batch, scripts de resolución de dependencias, reporteadores de estado de flota. No es participación comunitaria teórica. Son practicantes construyendo herramientas para sus propios workflows y publicándolas.
Coordinación orientada a agentes
La mayoría de los issue trackers tratan "automatización" como un webhook que se dispara cuando un humano cambia un status. Eso es adaptar una API a un workflow diseñado para humanos. beads y Beadbox fueron diseñados desde el principio para la coordinación de agentes IA.
Identidad estructurada de agentes. Cada agente tiene un archivo CLAUDE.md que define su rol, límites y protocolo de comunicación. Las flags --actor y --author del CLI bd vinculan cada acción a un agente específico. Cuando eng2 toma una tarea y publica un plan, el sistema sabe que fue eng2, no una "automatización" genérica.
El comando bd prime. Ejecuta bd prime en cualquier workspace y produce un bloque de contexto diseñado para asistentes de codificación IA. Pégalo en el prompt de sistema de tu agente y conocerá el set completo de comandos, formatos de salida y patrones de workflow. Enseñar a un nuevo agente a usar beads toma un comando, no una página de documentación.
Grafos de dependencia que los agentes realmente usan. Los agentes no trabajan con tableros Kanban. Trabajan con árboles y bloqueadores. beads rastrea relaciones padre/hijo y dependencias de bloqueo nativamente. bd blocked muestra cada bead esperando algo más. bd ready muestra todo lo que está desbloqueado y listo para trabajar. Beadbox renderiza esto como un árbol de dependencias interactivo donde puedes ver de un vistazo qué está trabado y por qué.
Visibilidad de flota en tiempo real. Beadbox vigila la base de datos beads y actualiza la UI en segundos. El Activity Dashboard muestra tarjetas de estado de agentes (quién está activo, quién silencioso, quién atascado), un flujo de pipeline (dónde se acumula el trabajo), y un feed de eventos con filtro cruzado (haz clic en un agente para ver solo sus acciones). Esta es la vista de "centro de misiones" que hace manejables 13 agentes en paralelo.
Eligiendo la herramienta correcta para tu equipo
Ninguna herramienta es universalmente correcta. Aquí hay un desglose honesto:
Elige Linear si:
- Tu equipo es de 10+ personas y necesita gestión de proyectos centralizada
- Dependes de integraciones con Slack/GitHub/Figma
- Stakeholders no técnicos necesitan acceso a tu issue tracker
- Quieres infraestructura gestionada con cero overhead operativo
- Eres un equipo de producto entregando en ciclos regulares
Elige Beadbox si:
- Valoras la soberanía de datos (los issues nunca salen de tu máquina)
- Trabajas offline regularmente o en entornos de red restringida
- Gestionas agentes IA que necesitan leer y escribir issues programáticamente
- Quieres historial de issues Git-native (branch, diff, merge en tus issues)
- Prefieres workflows CLI-first con un complemento visual cuando lo necesites
- Eres desarrollador solo o equipo pequeño (1-10) que no necesita features enterprise
Mantén tu herramienta actual si:
- El costo de cambio excede la fricción que experimentas
- Tu equipo ha invertido en integraciones que dependen del API de tu tracker actual
- Tu workflow ya encaja con las opiniones de tu herramienta
Migrando desde Linear (u otros trackers)
Seamos directos: no existe una herramienta automatizada de migración de Linear a Beadbox hoy. Sin wizard de importación CSV, sin puente API, sin UI de mapeo de status.
Si empiezas desde cero, perfecto. bd init, empieza a crear issues, y Beadbox los ve inmediatamente. Fricción cero.
Si tienes un proyecto Linear existente que quieres traer, el camino viable ahora es por script: exporta del API de Linear (soportan exportación CSV y por API), transforma los datos, y usa bd create en un bucle para recrear issues. Perderás metadatos específicos de Linear (ciclos, vistas de proyecto, timers de SLA) pero preservarás títulos, descripciones, prioridades y status. Un script de migración es un proyecto de fin de semana, no una integración de un trimestre.
Sabemos que esto no es suficiente para equipos con miles de issues y años de historial. Construir un pipeline de importación adecuado está en nuestro roadmap pero aún no está disponible. Si la fricción de migración es tu preocupación principal, espera hasta que lo hayamos construido, o evalúa si empezar desde cero es aceptable para tu caso de uso.
Empezando
Beadbox es gratuito durante la beta. Instálalo con Homebrew:
brew tap beadbox/cask && brew install --cask beadbox
Si ya usas beads, Beadbox detecta tus workspaces .beads/ existentes automáticamente. Abre la app y tus issues están ahí. Sin paso de importación. Sin creación de cuenta.
Si eres nuevo en beads, Beadbox te guía a inicializar tu primer workspace. Estarás viendo tus issues en menos de 60 segundos.
Descarga Beadbox o echa un vistazo a beads para ver si el issue tracking local-first encaja en tu workflow.