Empezaste con un solo servidor MCP. Acceso a archivos, para que tu agente Claude Code pudiera leer y escribir tu proyecto. Razonable.
Luego agregaste busqueda web. Luego GitHub. Luego una herramienta de base de datos para que el agente pudiera consultar tu esquema directamente. Luego Slack, porque el agente necesitaba revisar un hilo para requisitos. Luego una herramienta de documentacion para tu wiki interno.
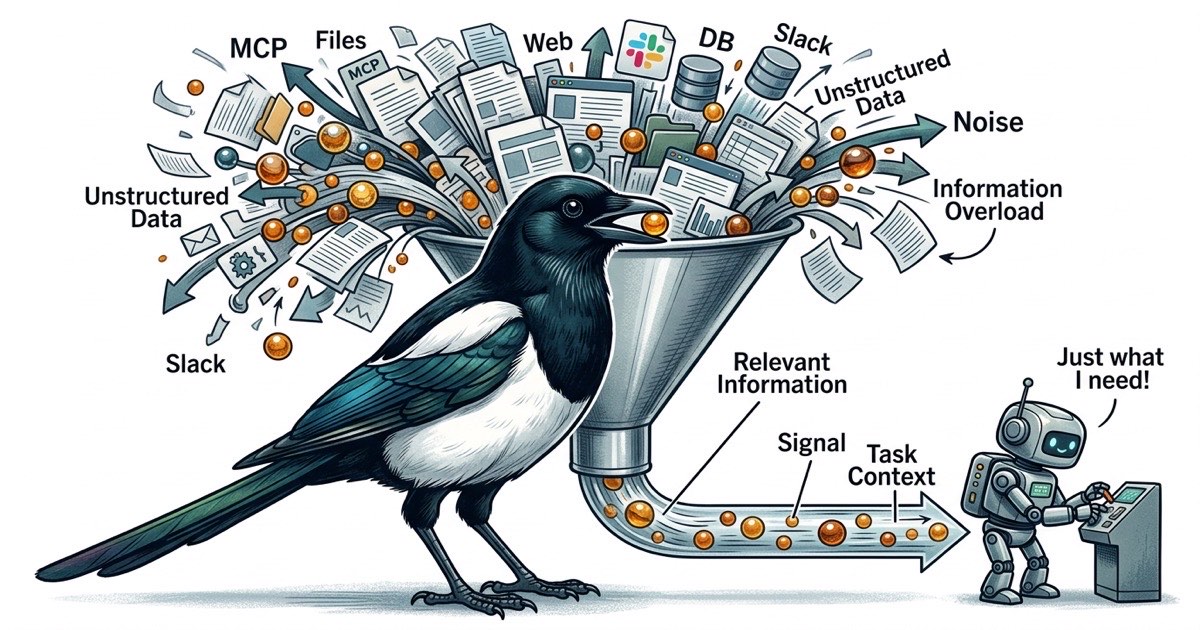
Seis servidores MCP. Cada uno registra schemas de herramientas en el contexto del agente. Cada uno amplia la superficie de lo que el agente podria hacer, lo que significa mas tokens gastados en descripciones de herramientas y mas oportunidades para que el agente se desvie del objetivo.
Tu agente sigue escribiendo buen codigo. Pero lo escribe mas lento, y los resultados se han vuelto menos predecibles. No te lo estas imaginando. La ventana de contexto es el cuello de botella, y la estas llenando con plomeria.
El problema de la acumulacion
Los servidores MCP son poderosos. El Model Context Protocol le da a Claude Code acceso a sistemas externos, y cada integracion resuelve genuinamente un problema. El acceso a archivos permite al agente leer tu codebase. La busqueda web le permite consultar documentacion. La integracion con GitHub le permite verificar el estado de PRs.
El problema comienza cuando resuelves cada necesidad del agente agregando otro MCP.
El agente necesita revisar el esquema de la base de datos? Agrega un MCP de Postgres. El agente necesita leer una pagina de Confluence? Agrega un MCP de Confluence. El agente necesita publicar un mensaje en Slack? Agrega un MCP de Slack. Cada uno esta justificado individualmente. En conjunto, crean un problema que es dificil de notar hasta que la calidad de los resultados cae.
Cada servidor MCP registra sus herramientas en el contexto de la conversacion. Un MCP de acceso a archivos podria registrar 5-10 herramientas. Un MCP de base de datos registra otro punado. Un MCP de GitHub agrega mas. Para cuando tienes seis servidores MCP, el agente carga decenas de definiciones de herramientas en su ventana de contexto antes de leer una sola linea de tu codigo.
Esas definiciones de herramientas no son gratis. Consumen tokens. Y mas importante, compiten por la atencion del agente. Cuando un agente tiene 40 herramientas disponibles, cada punto de decision se convierte en una pregunta ramificada: debo usar la herramienta de archivos, la de busqueda, la de base de datos o la de GitHub? El agente gasta presupuesto cognitivo decidiendo como obtener informacion en lugar de usar informacion para resolver tu problema.
El contexto es finito. La atencion es mas escasa.
La ventana de contexto de Claude Code es grande. Eso crea una ilusion peligrosa: que puedes seguir agregando informacion sin consecuencias.
En la practica, el rendimiento del agente se degrada mucho antes de que la ventana de contexto se llene. El problema no es la capacidad. Es la relacion senal-ruido. Un agente con una ventana de contexto de 200K tokens rinde mejor con 50K tokens de informacion enfocada y relevante que con 150K tokens donde los fragmentos relevantes estan dispersos entre schemas de herramientas, respuestas de API y contenidos de archivos tangenciales.
Es el mismo problema que enfrentan los humanos con demasiadas pestanas del navegador. La informacion esta tecnicamente disponible. Encontrarla toma mas tiempo del necesario. Terminas releyendo cosas que ya viste porque el contexto relevante fue desplazado de la memoria de trabajo por el ruido.
Para los agentes, esto se manifiesta como:
Madrigueras de conejo. El agente tiene una herramienta de base de datos, asi que consulta el esquema. El esquema es interesante, asi que consulta datos. Los datos revelan algo inesperado, asi que investiga mas. Veinte minutos despues, tienes un analisis exhaustivo del contenido de tu base de datos y cero progreso en la funcionalidad que pediste.
Confusion de herramientas. Con muchas herramientas disponibles, el agente ocasionalmente elige la incorrecta. Usa la busqueda web para encontrar documentacion que ya esta en un archivo local. Consulta la base de datos cuando la respuesta esta en la descripcion de la tarea. Cada eleccion erronea de herramienta desperdicia tokens e introduce ruido.
Foco diluido. La "atencion" del agente es un recurso finito dentro de cada generacion. Cuando el contexto contiene schemas de herramientas para acceso a archivos, busqueda web, consultas de base de datos, operaciones de GitHub, mensajes de Slack y consultas de wiki, el agente procesa todo eso antes de procesar tu solicitud real. La tarea compite con las herramientas por la prioridad cognitiva.
Contexto acotado: la alternativa a la proliferacion de herramientas
La respuesta reflexiva a "mi agente necesita la informacion X" es darle al agente una herramienta que obtenga X. Pero hay otro enfoque: poner X en la tarea.
Este es el patron de contexto acotado. En lugar de dar a los agentes acceso a todo y esperar que encuentren lo relevante, le das a cada agente una tarea que contiene todo lo que necesita para completar el trabajo. El agente no busca contexto. El contexto se le entrega.
La diferencia es estructural. Con proliferacion de MCPs, el flujo de trabajo del agente se ve asi:
- Leer la tarea
- Determinar que informacion falta
- Usar varias herramientas para recopilar esa informacion
- Sintetizar la informacion
- Hacer el trabajo real
Con contexto acotado, se ve asi:
- Leer la tarea (que contiene todo el contexto necesario)
- Hacer el trabajo real
Los pasos 2-4 del primer flujo no son solo overhead. Ahi es donde las cosas salen mal. El agente recopila demasiada informacion, o la informacion equivocada, o se distrae con datos interesantes pero irrelevantes. Cada invocacion de herramienta es un desvio potencial.
Contexto acotado no significa que los agentes no puedan usar herramientas. El acceso a archivos sigue siendo necesario para leer y escribir codigo. Pero significa que el contexto informativo (que construir, por que, que archivos, cuales son los criterios de aceptacion) vive en la tarea, no en una herramienta que el agente debe consultar.
Estructurando tareas como contenedores de contexto
Una tarea que funciona como contenedor de contexto se ve diferente a un ticket tipico de Jira o un issue de GitHub. Es autocontenida. Un agente que la lee deberia tener todo lo que necesita para comenzar a trabajar sin consultar sistemas externos para obtener informacion de fondo.
Asi se ve en la practica:
Title: Add rate limiting to /api/search endpoint
Description:
The /api/search endpoint currently has no rate limiting.
Add a token bucket rate limiter at 100 requests/minute per IP.
Files to modify:
- server/middleware/rate-limit.ts (create new)
- server/routes/search.ts (apply middleware)
- server/config.ts (add RATE_LIMIT_RPM env var)
Acceptance criteria:
- Requests beyond 100/min from same IP return 429
- Rate limit resets after 60 seconds
- Config value overridable via environment variable
- Existing tests still pass
Context:
- We use Express middleware pattern (see server/middleware/auth.ts for example)
- The config module uses dotenv (see server/config.ts lines 1-15)
- No Redis available; use in-memory store. This is a single-instance app.
Dependencies: None. This can run independently.
Observa lo que esta incluido en la tarea. El agente sabe que archivos tocar, que patron seguir, que restricciones existen (sin Redis), y exactamente como se ve "terminado." No necesita un MCP de base de datos para verificar el esquema. No necesita una herramienta de wiki para encontrar el patron de middleware. No necesita buscar en el codebase para entender el enfoque de configuracion. Todo esta en la tarea.
Escribir tareas asi requiere mas esfuerzo inicial. Un ticket tipico podria decir "Agregar rate limiting al endpoint de busqueda" y dejar que el agente descifre el resto. Pero ese proceso de descifrar es exactamente de donde viene la proliferacion de MCPs: el agente necesita informacion, asi que le das herramientas, y las herramientas consumen contexto.